
Mit der AIME API können Deep-Learning-Modelle (PyTorch, TensorFlow) über eine Job-Queue als skalierbare API-Endpunkte bereitgestellt werden. Ein solcher API Endpunkt ist in der Lage, Millionen von Modell-Inferenzanfragen zu verarbeiten. Damit lässt sich ein Python-Konsolen-Skript in eine sichere und robuste Web-API transferieren, die als Ihre Schnittstelle zur mobilen, Browser- und Desktop-Welt fungiert.
Mehr als ein modernes, leistungsstarkes und skalierbares Model Inferenz API Framework
Die Bereitstellung von KI-Modellen ist für die meisten Unternehmen eine Herausforderung. Sie stehen vor der Aufgabe, ihre Modelle schnell, skalierbar und sicher für den Einsatz in verschiedenen Entwicklungsumgebungen firmenintern oder öffentlich zugänglich zu machen.
Auf Basis der AIME API lassen sich nun kurzfristig und unkompliziert herausragende KI-Services bereitstellen, die sich mit wachsendem Bedarf und wachsender Anfrage skalieren lassen. Der asynchrone und multiprozessfähige API-Server ermöglicht eine schnelle Verarbeitung von Anfragen, während die verteilte clusteroptimierte Architektur Skalierbarkeit und Robustheit gewährleistet. Die Schnittstelle ist typensicher und validiert alle Eingaben, bietet Unternehmen also eine hohe Sicherheit.
Die Integration der AIME API in vorhandene Python- und TensorFlow-Projekte ist einfach und unkompliziert möglich. Entwickler und Unternehmen können eigene, sowie Open Source Modelle problemlos in die AIME API integrieren. Leistungsstarke Funktionen für die Umwandlung von Eingangsdaten, wie Bild- und Audio-Daten, stehen bereit.
Durch die moderne JSON basierte HTTPS Schnittstelle ist es unkompliziert, API-Anbindungen für eine Vielzahl von Programmiersprachen umzusetzen. Aktuell stehen Python- und JavaScript-Schnittstellen zur Verfügung, weitere sollen folgen. Dies macht die AIME API zu einer vielseitigen Lösung für Entwickler, StartUps und Unternehmen aller Größenordnungen, die ihre KI-Funktionen nutzbar und zugänglich machen möchten.
AIME API Features
- Schnell: Asynchron und multiprozessfähiger API-Server
- Skalierbar & Robust: Verteilte Cluster-optimierte Architektur
- Sicher: Typensichere Schnittstelle mit Eingabevalidierung
- Aggregierung von API-Anfragen zu GPU-Batch-Jobs für maximale Durchsatzleistung
- Einfache Integration in vorhandene Python- und TensorFlow-Projekte
- Hohe Leistung: Bild- und Audioumwandlung für gängige Medienformate
- Pythonic: API-Schnittstelle leicht übertragbar in Ihre bevorzugte Programmiersprache
Übersicht der AIME-API-Architektur
Die AIME API Serverlösung umfasst eine verteilte Serverarchitektur, die einen zentralen API-Server verwendet, der über eine Job-Warteschlange mit einem skalierbaren GPU-Computernetzwerk kommuniziert. Das GPU-Computernetzwerk kann heterogen sein und an verschiedenen Standorten verteilt werden, ohne dass eine direkte Verbindung erforderlich ist.
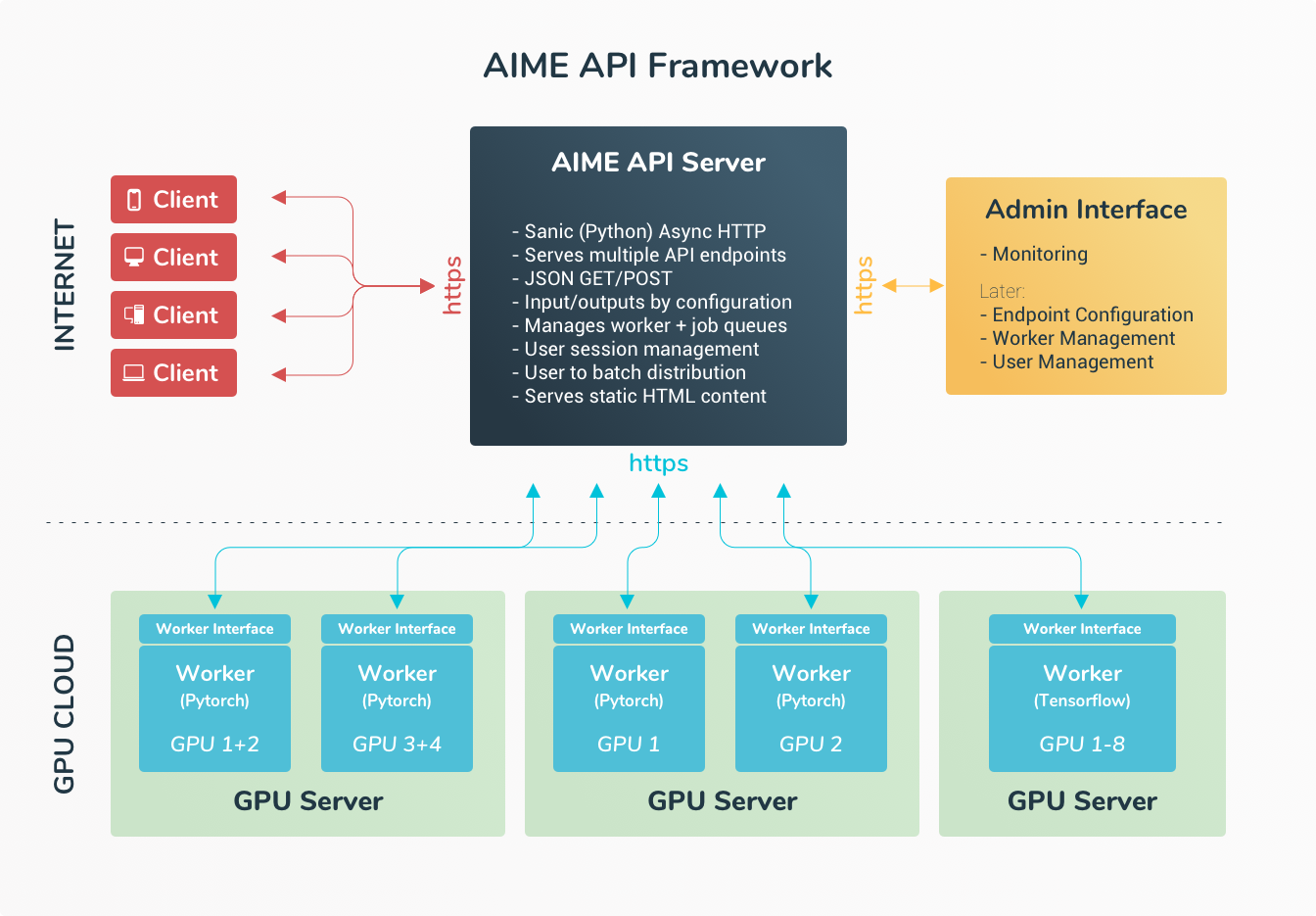
AIME API Server
Der Kern der AIME-API ist der API-Server, ein effizienter asynchroner HTTP/HTTPS-Webserver. Dieser kann als eigenständiger Webserver fungieren oder in Apache, NGINX oder ähnliche Webserver integriert werden. Er empfängt Clientanfragen, verteilt sie und leitet sie an die API-Compute-Worker weiter.
API Compute Workers
Die Client-Anfragen für die KI-Modelle werden von sogenannten Compute-Workern verarbeitet, die über eine sichere HTTPS-Schnittstelle mit dem API-Server verbunden sind. Durch Integration der AIME-API-Benutzerschnittstelle können bestehende PyTorch- und TensorFlow-Skripte problemlos in einen API-Compute-Worker umgewandelt werden.
Die Lokalität der Compute-Worker kann unabhängig vom API-Server sein. Sie benötigen lediglich Internetzugang, um Jobs anzufordern und die Berechnungsergebnisse zu senden. Die Compute-Worker werden in der Regel auf Multi-GPU-Servern oder Workstations ausgeführt, die sich hinter einer sicheren Firewall befinden oder sich in einer dedizierten HPC-Server-Colocation befinden können.
Clients
Clients wie Webbrowser, Smartphones, Desktop-Apps oder andere Server können Modellinferenz-API-Aufrufe problemlos über die AIME-API-Benutzerschnittstellen integrieren und ihre Anfragen über eine einfache, sichere und effiziente JSON-HTTPS-Schnittstelle senden. Für kurze Laufzeitaufträge kann das Ergebnis des Berechnungsauftrags direkt als JSON-Antwort empfangen werden, wobei alle Medien im Response-Stream enthalten sind. Für längere Prozessanfragen, wie etwa die Konvertierung oder Generierung von Multimedia-Inhalten (Bilder, Videos, Audio), steht eine leicht integrierbare Fortschritts-Schnittstelle zur Verfügung (Progress Interface).
Der AIME API-Server im Detail
Der AIME API-Server basiert auf dem asynchronen Python-Webframework Sanic, der ein performantes und effizientes Handling von HTTP/HTTPS-Anfragen bietet. Er kann als eigenständiger Webserver betrieben werden, der statische Dateien bereitstellt oder in weit verbreitete Webserver wie Apache und NGINX über die Mod-Proxy-Schnittstelle integriert werden.
Der AIME API-Server kann mehrere Endpunkte hosten, die gleichzeitig API-Zugriff auf verschiedene Modelle ermöglichen. Jeder Endpunkt wird mit einer intuitiv verständlichen Konfigurationsdatei eingerichtet, in der die erlaubten und erwarteten Eingabeparameter definiert sind, sowie das Ausgabe-Format der Ergebnisse festgelegt wird.
Für die Eingabe- und Ausgabeoptionen einer solchen Konfiguration könnten z.B. folgende Parameter definiert sein:
[INPUTS]
prompt = { type = "string", default = "", required = true }
negative_prompt = { "string", default = "" }
num_samples { type = "integer", min = 1, max = 10, default = 1 }
seed = { type = "integer", default = -1 }
height = { type = "integer", min = 512, max = 2048, default = 768 }
width = { type = "integer", min = 512, max = 2048, default = 768 }
[OUTPUTS]
images = { type = "image_list", format = "JPG", color_space = "RGB" }
seed.type = "integer"
prompt.type = "string"
Der AIME API-Server nimmt die Client-Anfragen entgegen, authentifiziert und validiert die Eingabedaten und wandelt Medien-Daten in definierte Auflösungen und gewünschte Formate um, um kompatible Eingaben zu generieren, die im jeweiligen Modell leichter verarbeitet werden können. Momentan werden Bild- und Audio-Daten verarbeitet, Video-Daten sollen aber bald hinzukommen.
Die Client-Anfragen werden validiert und gesammelt, um als parallel abarbeitbare Modell-Berechnungen per Job-Queues optimal vorverarbeitet auf die GPU(s) verteilt zu werden. Anfragen können so aggregiert werden, um als Job Batches verarbeitet zu werden, was die Auslastung der GPU und damit den maximal möglichen Durchsatz der abgearbeiteten Anfragen pro Zeit erheblich steigert.
Für die Verarbeitung von Anfragen, die nicht in Echtzeit verarbeitet werden können, können auch fein abgestimmte Fortschrittsaktualisierungen definiert werden.
[PROGRESS]
progress_images = { type = "image_list", format = "JPG", width=256, height=256, color_space = "RGB"}Das AIME API Compute Workers Interface
Durch Integration der AIME API Worker-Schnittstelle können vorhandene PyTorch- und TensorFlow-Skripte ganz einfach in einen AIME API Compute-Worker umgewandelt werden. Momentan als Python PIP-Paket verfügbar, kann die Schnittstelle unkompliziert um weitere Programmiersprachen erweitert werden.
Die Schnittstelle besteht hauptsächlich aus drei Aufrufen:
- Warten auf einen Job und Abrufen der Eingabeparameter für den Berechnungsauftrag.
- Im Falle längerer Jobs: Senden von Statusaktualisierungen oder Zwischenergebnissen.
- Senden des endgültigen Jobergebnisses.
Diese Integration kann nach dem Laden des Modells in einem Loop implementiert werden, um Jobs zu verarbeiten, ohne das Modell für jede Anfrage neu laden zu müssen. Dies ermöglicht deutlich schnellere Reaktionszeiten im Vergleich zum Starten eines neuen Skripts für jeden Berechnungsauftrag.
Mehrere Worker können auf einer einzelnen GPU gestartet, auf verschiedene GPUs verteilt oder, im Falle eines zu großen Modells, als Multi-GPU-Worker definiert werden. Die Worker können unabhängig auf verschiedenen Servern und einer Vielzahl von GPU-Modellen gestartet werden. Im Falle eines unerwarteten Absturzes oder der erforderlichen Abschaltung eines Workers sorgt der AIME API-Server für eine nahtlose Verteilung der Arbeitslast auf andere Worker, indem er die betroffenen Jobanfragen den verfügbaren Compute-Workern zuweist.
Das Client-Interface
Die AIME API bietet eine einfache und robuste JSON-Schnittstelle über HTTP/HTTPS.
Eine typische Anfrage, in diesem Beispiel eine Anfrage zur Erstellung eines Bildes aus einem Textprompt, würde wie folgt aussehen:
{
"client_session_auth_key": "f0aae4d5-abe5-49eb-a176-1129a14ec3a7",
"prompt": 'Astronaut on Mars during sunset sitting on a giant rubber duck',
"negative_aesthetic_score": 5,
"negative_prompt": "out of frame, lowres, text, error, cropped, low quality, extra fingers, bad proportions",
"num_samples": 1,
"seed": -1,
"width": 1024,
"height": 1024,
"wait_for_result": true,
}Da "wait_for_result" auf "true" gesetzt ist, wird die Antwort vom API-Server in wenigen Sekunden verfügbar, abhängig von der Auslastung und der Rechenleistung:
{
"success":true,
"ep_version":0,
"job_state":"done"
"job_result":
{
"seed":34953939,
"prompt":"Cat in Berlin",
"compute_duration":3.1,
"images":["data:image/JPEG;base64,... "]
}
}Alle Daten werden direkt vom Server empfangen, es sind keine Seitenkanäle erforderlich.
Für Anfragen, die länger zur Verarbeitung benötigen, wie z.B. die Erstellung von Mediadaten, wie Bilder oder Videos, oder die vollständige Übersetzung von Dokumenten, ist der Mechanismus für Fortschrittsaktualisierungen einfach zu aktivieren. In diesem Fall kann "wait_for_result" auf false gesetzt werden und der Server antwortet sofort mit:
{
"success":true,
"job_id":"JID2887"
}Mit der job_id kann der Fortschritt des Berechnungsauftrags verfolgt werden, indem der Status des Jobs abgefragt wird. Wenn der Job abgeschlossen ist, wird das endgültige Ergebnis empfangen.
Auch Mechanismen für Authentifizierung und Client-Autorisierung sind einfach und unkompliziert gehalten. Einfache Out-of-the-Box-Client-Implementierungen sind derzeit für JavaScript (JS) und Python verfügbar und lassen sich leicht auf alle Programmiersprachen übertragen. Weitere Implementierungen werden bald verfügbar sein, etwa die Schnittstellen für Android, iOS, Java, PHP, C/C++.
Sie können aber auch gerne Ihre eigenen hinzufügen!
AIME API Admin Interface
Ein weiteres geplantes Feature der AIME API, die Bereitstellung eines Admin-Backends zum Monitoring der Anfragebelastung, zur Verwaltung von Endpunkten, Workern und aktuellen Benutzern wird demnächst verfügbar sein.
Verfügbare Beispiel KI-Modelle
Um die Verwendung der AIME API zu veranschaulichen, hosten wir derzeit die folgenden Beispielmodelle, einschließlich ihrer Quellen auf GitHub.

Chatten mit 'Steve', unserem Chatbot auf Basis von LLaMa3.
- Demo: LLama3 Chat
- Source: https://github.com/aime-labs/llama3_chat

Chatten mit 'Dave', unserem Chatbot auf Basis von LLaMa2.
- Demo: LLama2 Chat
- Source: https://github.com/aime-labs/llama2_chat

Fotorealistische Bilder aus Textbeschreibungen erstellen.
In beinahe Echtzeit zwischen 36 Sprachen übersetzen: Text-zu-Text, Sprache-zu-Text, Text-zu-Sprache und Sprache-zu-Sprache!
Performance Benchmarks
Die AIME API skaliert nahezu linear mit der Anzahl der verfügbaren Worker. Im Folgenden finden sich einige Benchmark-Ergebnisse, um dies zu veranschaulichen. Für das Llama2-Chat 7B-Modell wurde mit einer A5000 24GB-GPU als Worker und einer Batch-Größe von 5 pro Worker gemessen, wie viele Ausgabetoken pro Sekunde generiert werden. Es wurden 1.000 Chat-Anfragen simuliert.
Der AIME API-Server zeigt eine lineare Skalierung des Durchsatzes mit der Anzahl der zur Verfügung stehenden Workern.
Ein KI-Model mit AIME-API-Server bereitstellen
Sie können einfach die oben genannten Demo-Worker ausprobieren, um ein Gefühl für die Architektur zu bekommen oder Ihr eigenes KI-Modell mit dem AIME-API-Server verbinden. Die Einrichtung Ihrer eigenen AIME-API-Lösung ist unkompliziert:
- Installieren Sie den AIME API Server auf Ihrem bevorzugten Webserver-Anbieter und verbinden Sie ihn mit Ihrer Internetdomain. Richten Sie ein HTTPS-Zertifikat ein, um eine sichere Verbindung zum API-Server zu ermöglichen.
- Erstellen Sie eine Konfigurationsdatei für Ihren API-Dienst, in der die Eingabe-, Ausgabe- und Intermediate-Parameter sowie die Serviceoptionen beschrieben werden.
- Integrieren Sie das AIME API Worker Interface in Ihr PyTorch-/TensorFlow-Skript und verbinden Sie die Eingabe- und Ausgabeparameter mit der Verarbeitung Ihres Modells.
- Starten Sie Ihren API-Compute-Worker, der an die URL, unter der der AIME-API-Server ausgeführt wird, angebunden ist. Ihre API ist jetzt einsatzbereit, um Anfragen zu verarbeiten.
- Mit dem AIME API Client Interface können API-Aufrufe problemlos als JavaScript-Methoden in Ihre Website integriert werden, oder mit der Python-Schnittstelle in Ihren auf Python basierenden Webserver. Schnittstellen für Android, iOS, Java, PHP, C/C++ sind in Arbeit.
Nutzung & Lizensierung
Die AIME API ist als Open Source auf GitHub verfügbar.
Die Nutzung für private und nicht kommerzielle Zwecke sowie kommerzielle Nutzung auf AIME-Servern (on-premise oder in der AIME-Cloud) ist kostenlos. Für andere kommerzielle Anwendungsfälle kontaktieren Sie uns bitte unter api@aime.info.
Wir freuen uns auch über aktive Zusammenarbeit, zum Beispiel bei der Erweiterung der API-Schnittstellen für andere Programmiersprachen oder bei der Anbindung und Bereitstellung weiterer Open-Source-KI-Modelle.



