
With AIME API one deploys deep learning models (PyTorch, TensorFlow) through a job queue as scalable API endpoint capable of serving millions of model inference requests.
Turn a console Python script to a secure and robust web API acting as your interface to the mobile, browser and desktop world.
AIME API Features
- Fast - asynchronous and multi process API server
- Scalable & robust- distributed cluster ready architecture
- Aggregate requests to GPU batch jobs for maximum throughput
- Secure - type safe interface and input validation
- Easy integrable into existing PyTorch and TensorFlow projects
- High performance image and audio input/output conversion for common web formats
- Pythonic - easily extendable in your favorite programming language
Overview AIME API Architecture
The AIME API server solution implements a distributed server architecture with a central AIME API server communicating through a job queue with a scalable GPU compute cluster. The GPU compute cluster can be heterogeneous and distributed at different locations without requiring an interconnect.
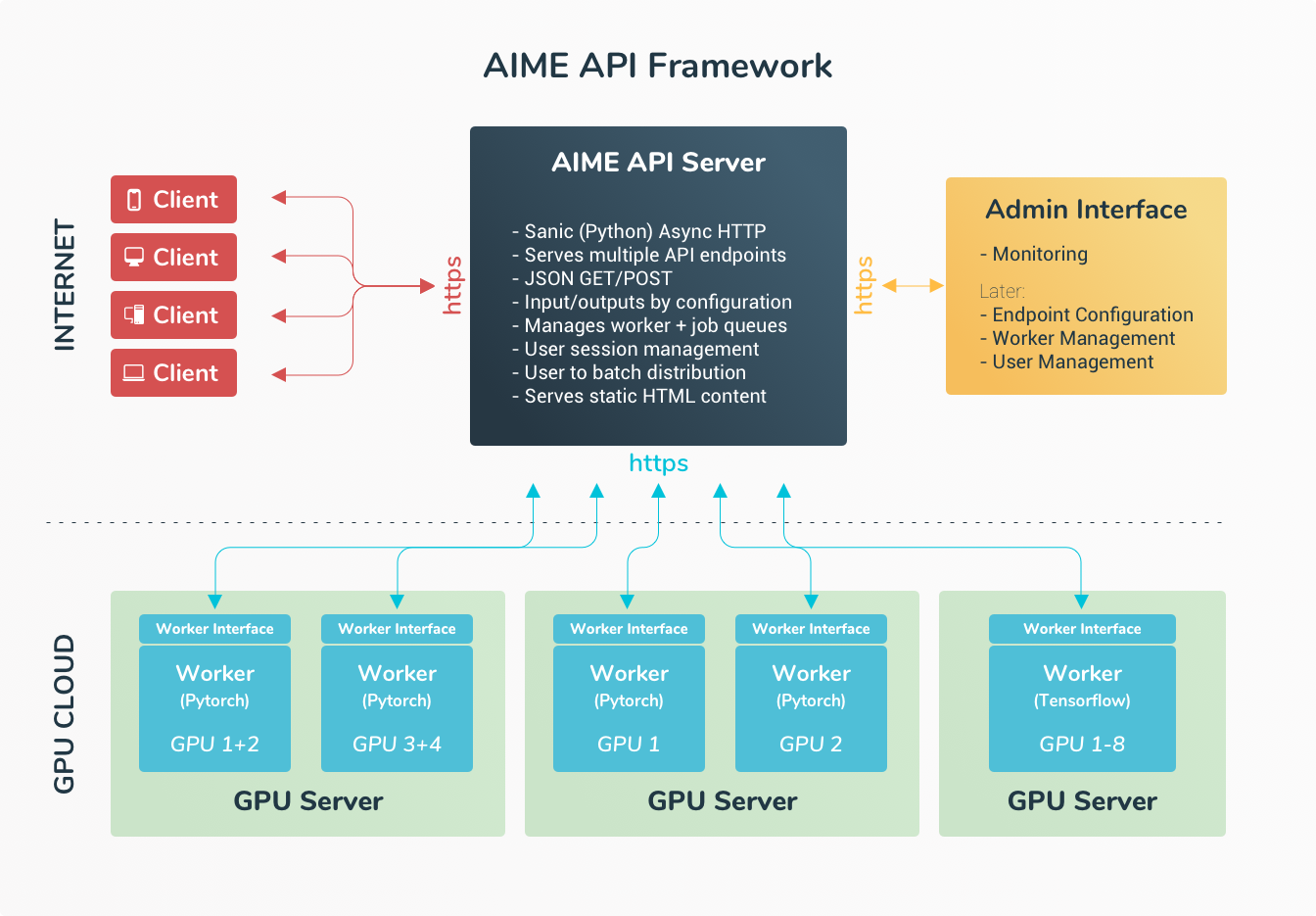
AIME API Server
The central part is the API Server, an efficient asynchronous HTTP/HTTPS web server which can be used stand-alone web server or integrated into Apache, NGINX or similar web servers. It takes the client requests, load balances the requests and distributes them to the API compute workers efficiently.
API Compute Workers
The model compute jobs are processed through so called compute workers which connect to the AIME API server through a secure HTTPS interface. The locality of the compute workers can be independent from the API server, they only need internet access to request jobs and send the compute results. Compute workers are usually running on multi GPU servers or workstations, which can reside behind a secure firewall or in a dedicated HPC server colocation.
Clients
Clients, like web browsers, smartphones, desktop apps or other servers using the AIME API as service can send request through a simple, secure and efficient JSON HTTPS interface. For short running jobs the result of the compute job can be received directly as response in JSON, all media is included in the response stream. For longer process request (like conversion or generation of multimedia content, like images, video or audio) there is an easy to integrate progress interface.
The AIME API Server in more detail
The AIME API Server is based on the asynchronous Python Sanic web framework for performant and efficient HTTP/HTTPS request handling. It can be used as stand-alone web server, being capable of serving static files efficiently or can be integrated in leading web servers like Apache and NGINX through the mod proxy interface.
The AIME API Server can host multiple endpoints which provide API access to different models simultaneously. Each endpoint can be configured with an intuitive configuration file, to declare the allowed and expected input parameters and the format the results are to be delivered.
As the input and output part of such a configuration:
[INPUTS]
prompt = { type = "string", default = "", required = true }
negative_prompt = { "string", default = "" }
num_samples { type = "integer", min = 1, max = 10, default = 1 }
seed = { type = "integer", default = -1 }
height = { type = "integer", min = 512, max = 2048, default = 768 }
width = { type = "integer", min = 512, max = 2048, default = 768 }
[OUTPUTS]
images = { type = "image_list", format = "JPG", color_space = "RGB" }
seed.type = "integer"
prompt.type = "string"
The AIME API server takes the client requests, authenticates and validates the input data and converts media (currently image and audio is handled, video is coming soon) to defined resolutions and desired formats to compatible input which can be processed in your model more easily.
The preprocess and validated client request are managed and load balanced in multiple distributed job queues as bite-size model compute requests. Also the requests can be aggregated to be processed as job batches, which can strongly increase the throughput and utilization of the GPU compute resources.
For processing requests which are not processable in real time also fine grained progress updates can be defined.
[PROGRESS]
progress_images = { type = "image_list", format = "JPG", width=256, height=256, color_space = "RGB"}The AIME API Compute Workers Interface
You can easily turn your existing PyTorch and TensorFlow script into an AIME API compute worker by integrating the AIME API Worker Interface.
It is currently available as Python PIP package, extendable to other programming language. It mainly consist of three calls:
- Wait for a job and get the input parameters for the compute job
- In case of lengthy jobs: send job status or intermediate results
- Send the final job result
This can be integrated after the model is loaded in a loop to process jobs without having to load the model for each request, giving much faster response times than starting a script for each compute request.
Multiple workers can be started on a single GPU, on different GPUs or in case of a too large model as a multi-GPU worker. Workers can be started independently on different servers and a variety of GPU models. In the event of a worker unexpectedly crashing or requiring shutdown, the seamless distribution of workload among other workers is ensured by the AIME API server, allocating the appropriate job requests to the available compute workers.
The Client Interface
The AIME API provides a simple and robust JSON interface through HTTP/HTTPS.
A typical request, in this example a request to create an image from a text prompt, would look like this:
{
"client_session_auth_key": "f0aae4d5-abe5-49eb-a176-1129a14ec3a7",
"prompt": 'Astronaut on Mars during sunset sitting on a giant rubber duck',
"negative_aesthetic_score": 5,
"negative_prompt": "out of frame, lowres, text, error, cropped, low quality, extra fingers, bad proportions",
"num_samples": 1,
"seed": -1,
"width": 1024,
"height": 1024,
"wait_for_result": true,
}As "wait_for_result" is true, the response from the API server will be available in a few seconds, depending on the load and compute power:
{
"success":true,
"ep_version":0,
"job_state":"done"
"job_result":
{
"seed":34953939,
"prompt":"Cat in Berlin",
"compute_duration":3.1,
"images":["data:image/JPEG;base64,... "]
}
}All data is sent inbound directly from the server, no side channels are required.
For requests taking longer to process, like video creation or complete document translations the mechanism for progress updates is easy to use. In this case "wait_for_result" can be set to false and the server will respond immediately with:
{
"success":true,
"job_id":"JID2887"
}With the job_id the progress of the compute request can be tracked by polling the status of the job. If the job is finished the final result will be received.
Also mechanisms for authentication and client authorization are kept simple and straight forward.
Easy out of the box client implementations are currently available for: Javascript (JS) and Python and are easily portable to all programming languages. More implementations will come soon as we are working on interfaces for Android, iOS, Java, PHP, C/C++. But please feel free to add you own!
AIME API Admin Interface
An upcoming feature of AIME API is to present an admin backend for monitoring the request load, manage endpoints, workers and current users. Coming soon!
Available Example Models
To illustrate the usage we currently host the following example models including their source on Github.

Chat with 'Steve', our LLaMa3 based chat-bot.
- Demo: LLama3 Chat
- Source: https://github.com/aime-labs/llama3_chat

Chat with 'Dave', our LLaMa2 based chat-bot.
- Demo: LLama2 Chat
- Source: https://github.com/aime-labs/llama2_chat

Create photo realistic images from text prompts.
Translate between 36 languages in near realtime: Text-to-Text, Speech-to-Text, Text-to-Speech and Spech-to-Speech!
Performance Benchmarks
AIME API scales nearly linear with the amount of workers available. Here are some benchmark to illustrate its performance:
Llama2-Chat 7B Model with A5000 24GB GPU as worker with batch size 5 per worker, measuring how many output tokens per seconds are generated. 1.000 chat requests where simulated.
The AIME API Server show linear scaling of performance with the amount of workers.
How to deploy your Model Inference API Server
You can just try out the upper demo workers to get a feeling for the architecture or connect your own AI model to the AIME API Server. Setting up your own AIME API solution is straight forward:
- Install the AIME API Server on your preferred web server provider and connect it to your internet domain. Setup a HTTPS certificate to enable a secure connection to the API Server.
- Create a config file for your API service describing the input, output, intermediate parameters and service options
- Incorporate the AIME API Worker Interface in your PyTorch/TensorFlow script and connect the input and output parameters to your model processing
- Start your API compute workers pointing to the URL the AIME API Server is running on, now your API is up and ready to process requests
- With the AIME API Client Interface one can easily integrate API calls as Javascript methods to your website or with the Python interface to your Python based web server. Interfaces for Android, iOS, Java, PHP, C/C++ are in the works.
Usage & Licensing
AIME API is available as open source on github.
Private and non commercial use and commercial use on AIME servers (on premise or in the AIME Cloud) is free of charge. For other commercial use cases, please contact us at api@aime.info.
We are also happy to receive active collaboration, for example in expanding the API interfaces for other programming languages or connecting and providing further open source AI models.




