
Im vorhergehenden Artikel unserer LLama-Serie haben wir detailliert demonstriert, wie sich das LLaMa-Instruct-Modell als Chatbot in einer Konsolenanwendung betreiben lässt. Im Folgenden soll nun dargestellt werden, wie sich das Nachfolgemodell LLaMa 2 unkompliziert mittels AIME-API-Server als Conversational-AI-Anwendung einrichten lässt.
• Llama 3 als Conversational-AI mittels AIME-API-Server betreiben
Die AIME API vereinfacht die Nutzbarmachung von KI-Modellen in Client-Anwendungen, z.B. als GenAI-Tool, und vereinfacht die Integration von Technologien wie LLaMa 2 als skalierbare HTTP/HTTPS-Dienste, womit das volle Potenzial moderner KI-Anwendungen freigelegt werden kann.
Für Entwickler von Chatbots, virtuellen Assistenten oder interaktiven Kundensupport-Systemen bietet diese Art der Anbindung die gewünschte Flexibilität, um jederzeit Modifikationen und Anpassungen am verwendeten Modell vornehmen zu können, sowie die benötigte Skalierbarkeit, um solche Lösungen als Dienst im großen Stil bereitzustellen.
Unsere LLaMa2-Implementierung ist ein Fork des Original-LLaMa 2-Repositorys und unterstützt alle LLaMa 2-Modellgrößen (7B, 13B und 70B). Wir bieten abweichend vom Original-LLaMa2-Modell zusätzlich noch die Möglichkeit, die Modell-Gewichte so zu konvertieren, dass man LLaMa 2 auf verschiedenen GPU-Konfiguration ausführen kann, das Modell also auf mehrere GPUs verteilen kann (siehe Tabelle 2).
Durch die Integration in die AIME-API wird es möglich, mittels Batch-Aggregation die Inferenzleistung entsprechend der vorhandenen GPU-Konfigurationen zu skalieren. Mit Hilfe des API-Servers werden also alle Anfragen als Batch-Jobs von den GPUs parallel verarbeitet. Dies erhöht die erreichbare Durchsatzleistung der Chat-Anfragen dramatisch.
Anhand der unten aufgeführten Benchmark-Tests mit verschiedenen GPU-Konfigurationen geben wir abschließend eine Antwort auf die Frage, welche Hardware die beste Durchsatzleistung für die Verarbeitung von LLaMa-Anfragen bietet.
Hardwareanforderungen
Obwohl die LLaMa2-Modelle auf einem Cluster von A100 80GB GPUs trainiert wurden, ist es möglich, die Modelle auf unterschiedlicher und kleinerer Multi-GPU-Hardware für die Inferenz auszuführen.
Um ein bestimmtes LLaMa 2-Modell mit Echtzeit-Leseleistung auszuführen, benötigt man die in Tabelle 1 aufgelistete minimale GPU-Konfiguration, die sich in den dort empfohlenen AIME-Systemen entsprechend wiederfinden:
| Model | Größe | Minimale GPU-Konfiguration | Empfohlener AIME-Server | Empfohlene AIME-Cloud-Instanz |
|---|---|---|---|---|
| 7B | 13GB | 1x Nvidia RTX A5000 24GB or 1x Nvidia RTX 4090 24GB | AIME G400 Workstation | V10-1XA5000-M6 |
| 13B | 25GB | 2x Nvidia RTX A5000 24GB or 1x NVIDIA RTX A6000 | AIME A4000 Server | V10-2XA5000-M6, v14-1XA6000-M6 |
| 70B | 129GB | 2x Nvidia A100 80GB, 4x Nvidia RTX A6000 48GB or 8x Nvidia RTX A5000 24GB | AIME A8000 Server | V28-2XA180-M6, C24-4X6000ADA-Y1, C32-8XA5000-Y1 |
Eine ausführliche Leistungsanalyse verschiedener Hardwarekonfigurationen findet sich im Abschnitt "LLaMa2 Inference GPU Benchmarks" dieses Artikels.
Los geht's: Wie man LLama2-Chat deployed
Die folgenden Schritte sind notwendig, um LLaMa 2 als Webanwendung betreiben zu können:
- Einrichten der Betriebsumgebung, unkompliziert mittels AIME MLC Framework
- Klonen des LLaMa2-Chat Repositories und Laden der LLaMa 2-Modellgewichte
- Testen des LLaMa 2-Modells als Konsolenanwendung
- Starten des API-Servers und des LLaMa 2-Workers zum Bedienen von HTTPS/HTTP-Anfragen
Erstellung eines AIME-ML-Containers
Für die unkomplizierte Einrichtung einer Betriebsumgebung nutzen wir das AIME-ML-Container-Management Framework. Hierfür lassen sich selbstverständlich auch andere Lösungen, wie Conda oder ähnliche Tools nutzen.
Um eine PyTorch 2.1.2-Umgebung für Installation und Betrieb des Modells zu erstellen, erstellen wir, wie in aime-ml-containers beschrieben, den AIME-ML-Container, mit dem folgenden Befehl:
> mlc-create llama2 Pytorch 2.1.2-aime -w=/pfad/zu/ihrem/workspace -d=/pfad/zu/den/checkpointsDer Parameter -d ist nur erforderlich, wenn Sie die Modell-Checkpoints nicht in Ihrem Arbeitsbereich (workspace), sondern in einem bestimmten Datenverzeichnis speichern möchten. Er bindet den Ordner /pfad/zu/den/checkpoints an den Pfad /data innerhalb des Container an. Dieser Ordner benötigt mindestens 250 GB freien Speicherplatz, wenn man alle) LLaMa-Modelle dort speichern möchte.
Sobald der Container erstellt ist, öffnet man ihn mit:
> mlc-open llama2Man arbeitet nun im virtuellen ML-Container (Docker) und kann alle Abhängigkeiten, wie erforderliche Pip- und Apt-Pakete dort bedenkenlos installieren, ohne das Host-System zu beeinträchtigen.
Klonen des LLaMa2-Chat Repositories
Das Repository LLaMa2-Chat ist eine von AIME geforkte (abgeleitete) Version der ursprünglichen LLaMa2-Referenzimplementierung von Meta mit den folgenden zusätzlichen Funktionen:
- Tool zur Konvertierung der originalen Modell-Checkpoints für verschiedene GPU-Konfigurationen
- Verbessertes Text-Sampling
- Token-weise Textausgabe
- Interaktiver Konsolen-Chat
- Integration in den AIME-API-Server
Das LLaMa2-Chat-Repository von AIME wird wie folgt geklont:
[llama2] user@client:/workspace$
> git clone https://github.com/aime-labs/llama2_chatAnschließend müssen die benötigten Pip-Pakete installiert werden:
[llama2] user@client:/workspace$
> pip install -r /workspace/llama2_chat/requirements.txtDownload des LLaMa 2 Modell-Checkpoints
Von Meta
Um die Modellgewichte und den Tokenizer herunterzuladen, muss man einen Zugriffsantrag bei Meta stellen und deren Lizenz akzeptieren. Sobald der Antrag genehmigt ist, erhält man eine signierte URL per E-Mail. Nun ist noch sicher zu stellen, dass wget und md5sum im Container installiert sind:
[llama2] user@client:/workspace$
> sudo apt-get install wget md5sumNachfolgend führt man das Skript download.sh aus:
[llama2] user@client:/workspace$
> /workspace/download.shNun muss man die bereitgestellte URL eingeben, wenn man zur Durchführung des Downloads aufgefordert wird. Es ist zu beachten, dass diese Links nach 24 Stunden und einer bestimmten Anzahl von Downloads ablaufen. Wenn Fehlermeldungen wie 403: Forbidden auftreten, kann man jederzeit einen neuen Link anfordern.
Von Huggingface
Um die Checkpoints und den Tokenizer über Huggingface herunterzuladen, muss man ebenfalls einen Zugang von Meta beantragen und deren Lizenz akzeptieren. Mit der gleichen Mailadresse muss man sich dann noch bei Huggingface registrieren.
Um Repositories mit großen Dateien von Hugginface klonen zu können, ist nun noch git lfs im Container zu installieren:
[llama2] user@client:/workspace$
> sudo apt-get install git-lfs
> git lfs installDie Checkpoints des 70B-Modells lädt man mit folgenden Befehlen herunter:
[llama2] user@client:/workspace$
> cd /destination/to/store/the/checkpoints
[llama2] user@client:/destination/to/store/the/checkpoints$
> git lfs clone https://huggingface.co/meta-llama/Llama-2-70b-chatUm die Modelle anderer Größen herunterzuladen, ersetzt man "Llama-2-70b-chat" durch "Llama-2-7b-chat" oder "Llama-2-13b-chat". Der Download-Vorgang kann je nach Geschwindigkeit der Internetverbindung einige Zeit in Anspruch nehmen. Für das 70B-Modell müssen 129 GB heruntergeladen werden. Man wird zweimal nach Benutzername und Passwort gefragt. Als Passwort wird der Zugriffstoken verwendet, der hierfür in den Kontoeinstellungen von Huggingface generiert werden muss.
Konvertieren der Checkpoints entsprechend der GPU-Konfiguration
Die heruntergeladenen Checkpoints sind nur für bestimmte GPU-Konfigurationen vorgesehen: 7B für 1x GPU, 13B für 2x GPUs und 70B für 8x GPUs. Um das Modell auf einer anderen GPU-Konfiguration ausführen zu können, stellt AIME ein Tool zur Verfügung, um die Modell-Gewichte entsprechend zu konvertieren. Tabelle 2 listet alle unterstützten GPU-Konfigurationen auf.
| Modelgröße | Anzahl GPUs 24GB | Anzahl GPUs 40GB | Anzahl GPUs 48GB | Anzahl GPUs 80GB |
|---|---|---|---|---|
| 7B | 1 | 1 | 1 | 1 |
| 13B | 2 | 1 | 1 | 1 |
| 70B | 8 | 4 | 4 | 2 |
Der Konvertierungsvorgang kann mit dem folgenden Befehl gestartet werden:
[llama2] user@client:/workspace$
> python3 /workspace/llama2_chat/convert_weights.py --input_dir /destination/to/store/the/checkpoints --output_dir /destination/to/store/the/checkpoints --model_size 70B --num_gpus <num_gpus>Die Konvertierung kann je nach CPU- und Speichergeschwindigkeit sowie Modellgröße einige Minuten dauern.
LLaMa 2 als interaktiven Chat im Terminal ausführen
Um die LLaMa2-Modelle als Chatbot im Terminal auszuprobieren, startet man das folgende PyTorch-Skript und gibt die gewünschte Modellgröße an, die verwendet werden soll:
[llama2] user@client:/workspace$
> torchrun --nproc_per_node <num_gpus> /workspace/llama2_chat/chat.py --ckpt_dir /data/llama2-model/llama-2-70b-chatDer Chat-Modus wird durch Angabe des folgenden Kontexts als Startprompt initiiert. Er setzt die Umgebung so, dass das Sprachmodell versucht, den Text als Chatdialog zu vervollständigen:
Ein Dialog, in dem der Benutzer mit einem hilfreichen, freundlichen, gehorsamen, ehrlichen und sehr vernünftigen Assistenten namens Dave interagiert.
Benutzer: Hallo, Dave
Dave: Wie kann ich Ihnen heute helfen?
Dadurch fungiert das Modell als einfacher Chatbot. Der Startprompt beeinflusst die Stimmung der Antworten des Chatbots. In diesem Fall erfüllt er glaubwürdig die Rolle einer hilfsbereiten Assistenten und verlässt sie auch nicht ohne Weiteres. Hierdurch können interessante, lustige bis hilfreiche Antworten entstehen - abhängig von den Eingabetexten.
LLaMa 2 Chat als Web-Service mit dem AIME-API-Server ausführen
Einrichten des AIME API Servers
Um den AIME-API-Server einzurichten und zu starten, finden sich alle Informationen im Abschnitt "Setup" der API-Dokumentation.
Starten von LLaMa2 als API-Worker
Um das LLama2-Chat-Modell mit dem AIME-API-Server zu verbinden, der bereit ist, Chat-Anfragen über die JSON-HTTPS/HTTP-Schnittstelle zu empfangen, fügt man einfach die Option --api_server gefolgt von der Adresse des AIME-API-Servers hinzu, mit dem Sie sich verbinden möchten:
[llama2] user@client:/workspace$
> torchrun --nproc_per_node <num_gpus> /workspace/llama2_chat/chat.py --ckpt_dir /data/llama2-model/llama-2-70b-chat --api_server https://api.aime.info/Nun fungiert das LLama 2-Modell als Worker-Instanz für den AIME-API-Server, bereit zur Verarbeitung von Jobs, die von Clients des AIME-API-Servers angefragt wurden.
Für die Dokumentation zum Senden von Client-Anfragen an den AIME-API-Server lesen Sie bitte hier weiter.
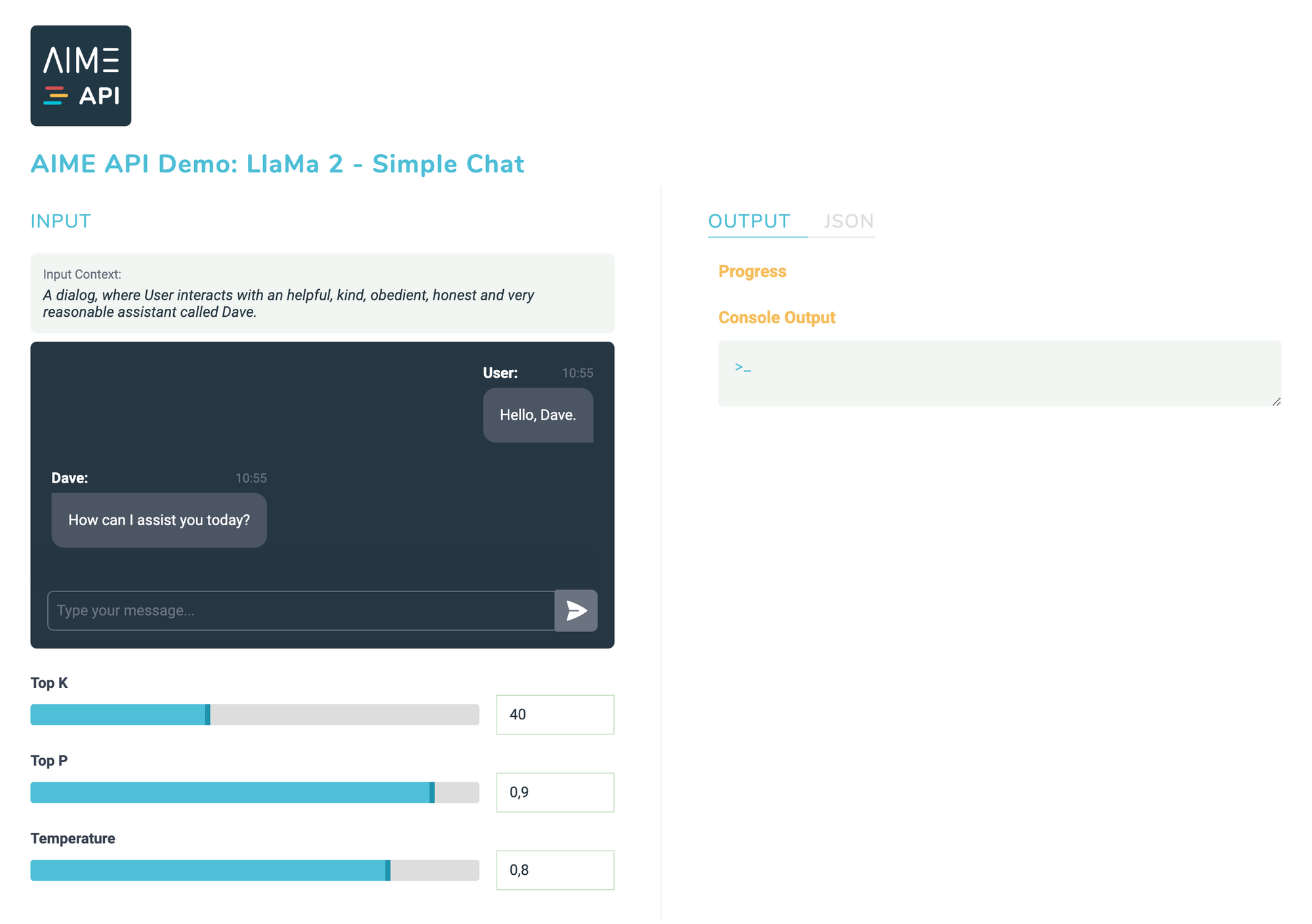
Testen des LLaMa2-Chats mit dem AIME API Demonstrator
Der AIME-API-Server bietet Client-Schnittstellen für verschiedene Programmiersprachen an. Um die Leistung von LLaMa 2 mit dem AIME API Server zu demonstrieren, stellen wir einen voll funktionsfähigen LLaMa2-Demonstrator unter Verwendung einer JavaScript-Client-Schnittstelle bereit.
LLaMa2-Inferenz GPU-Benchmarks
Um die Leistung des mit dem AIME-API-Server verbundenen LLaMA2-Workers zu messen, liegt dem AIME-API-Server ein Benchmark-Tool bei, mit dem der Server als Simulation mit einer beliebigen Anzahl von Chat-Anfragen belastet werden kann. Um die Messung anstoßen zu können, müssen vorerst alle erforderlichen Abhängigkeiten installiert werden:
user@client:/workspace/aime-api-server/$
> pip install -r requirements_api_benchmark.txtDaraufhin kann das Benchmark-Tool mit folgendem Befehl gestartet werden:
user@client:/workspace/aime-api-server/$
> python3 run_api_benchmark.py --api_server https://api.aime.info/ --total_requests <number_of_requests>run_api_benchmark.py sendet so viele Anfragen wie möglich parallel und bis zu <number_of_requests> Chat-Anfragen an den API-Server. Jede Anfrage beginnt mit dem Ausgangskontext "Es war einmal". LLaMa2 generiert, abhängig von der verwendeten Modellgröße, eine Geschichte von etwa 400 bis 1000 Token Länge. Die verarbeiteten Tokens pro Sekunde werden gemessen und über alle verarbeiteten Anfragen gemittelt.
Ergebnis
Im Folgenden werden die Benchmark-Ergebnisse der verschiedenen LLaMa2-Modellgrößen und GPU-Konfigurationen gelistet. Das Model wird so geladen, dass die GPUs es im Batchbetrieb nutzen können. Die maximal mögliche Batchgröße, die der Anzahl der parallel verarbeitbaren Chat-Sitzungen entspricht, wird in den unten stehenden Abbildungen unterhalb des GPU-Modells angegeben und steht im direkten Zusammenhang mit dem verfügbaren GPU-Speicher.
Die Ergebnisse werden dargestellt als Gesamtdurchsatz in Tokens pro Sekunde, die kleineren Balken zeigen die Tokens pro Sekunde für einzelne Chat-Sitzungen.
Die menschliche (stille) Lesegeschwindigkeit beträgt etwa 5 bis 8 Wörter pro Sekunde. Mit einem Verhältnis von 0,75 Wörtern pro Token entspricht dies einer erforderlichen Generierungsgeschwindigkeit von etwa 6 bis 11 Tokens pro Sekunde, um bei der Textausgabe als nicht zu langsam wahrgenommen zu werden.
LLaMa 2 7B GPU Performance
LLaMa 2 13B GPU Performance
LLaMa 2 70B GPU Performance
Zusammenfassung
Die Integration von LLaMa 2 in die AIME-API und die einfache und schnelle Einrichtung des API-Servers eröffnet Entwicklern eine komfortable, skalierbare Lösung für die Bereitstellung von Conversational-AI-Lösungen. Die Integration von LLaMa 2 in den AIME-API-Server ermöglicht die einfache Erstellung hochperformanter, professioneller Anwendungen, wie Chatbots, virtuellen Assistenten oder interaktiven Kundensupportsystemen.
Die Flexibilität der Hardware-Anforderungen für das Ausführen von LLaMa-2-Modellen wird durch die Möglichkeit der verteilten Verarbeitung auf mehreren GPUs maximiert. Diese Flexibilität ermöglicht das skalierbare Deployment auf unterschiedlichsten GPU-Konfigurationen mit erweiterbaren Setups und Infrastrukturen, die in der Lage sind, tausende von Anfragen gleichzeitig zu bedienen. Sogar die minimalen GPU-Anforderungen und die kleinsten empfohlenen AIME-Systeme für jede der Modellgrößen garantieren eine Reaktionsgeschwindigkeit beim Lesen der Textausgabe, die über Echtzeit liegt und somit ein angenehmes Chat-Erlebnis für viele gleichzeitig aktive Nutzer bietet.
• Llama 3 als Conversational-AI mittels AIME-API-Server betreiben




