
In our previous articles about the Llama models (Llama 2, Llama 1), we delved into the details of running Llama as console application as well as deploying it via the AIME API Server. Embracing the next step with Llama 3, the most recent advancement in the realm of open large language models, we will now provide a comprehensive guide on how to set up Llama 3 and operate it with the AIME API server, opening up new possibilities for delivering AI conversational experiences.
At AIME, we understand the importance of providing AI tools as services to harness the full potential of technologies like Llama. That's why we're excited to announce the integration of Llama 3 with our new AIME-API as one of the first providers, offering developers a streamlined solution for delivering its capabilities as a scalable HTTP/HTTPS service for easy integration with client applications. Whether you're building chatbots, virtual assistants, or interactive customer support systems, this integration offers flexibility to make modifications and adjustments to the model and the scalability to deploy such solutions.
What is new with Llama 3
As you may already know, there are two previous versions of the Llama model - so what is the advantage of Llama 3 over the older versions?
The main improvement is the 8K context length, which doubles the previous 4K context length of Llama 2 and quadruples the 2K of the original Llama models. 8K context length equals about 6.000 words which represents about 12 standard A4 (letter size) pages of text. This is a good length to operate a chat bot with a detailed instructions manual or playbook to cover lengthy conversations, remembering every detail of the conversation.
Although the model sizes did not increase dramaticly due to an improved and better curated training data set - a training dataset 7x larger than that used for Llama 2 - all Llama 3 models show a huge improvement in nearly all LLM benchmarks, putting it on par with most closed source state-of-the-art models.
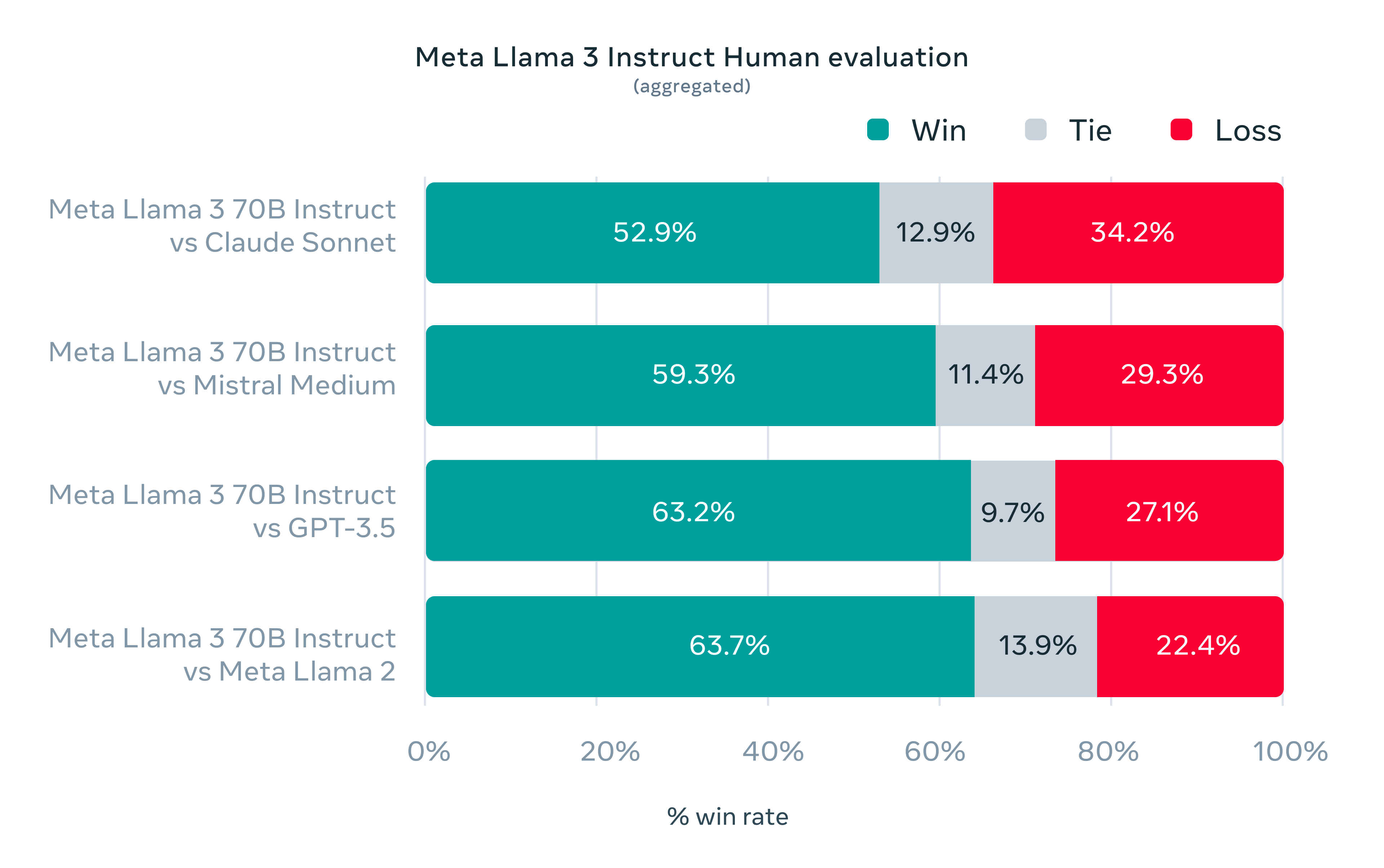
Also chatting with Llama 3 one notices a far more friendly, helpful and enganging large language model than the previous versions.
The 7B model was tuned to an 8B model to make better use of 24 GB GPU memory which has established as the standard on entry deep learning GPUs. The 13B model was dropped for the improved 70B model.
There are rumours that Meta is still computing on an even larger model to be released later in the year. Let's wait and see.
Ready for Instructions: The LLama3 Instruct Mechanism
The Llama 3 models come in two flavours: the generic version and the instruct version. The instruct versions are fine tuned with the so called „Instruct“ training set, to turn the generic language model into a model that understands the so called „instruct syntax“.
The fine tuning of the model turns the generic language model, which initial purpose is to continue writing a text fragment, into a chat assistant that can be controlled with a „system prompt“ giving instructions: what is important, in which context and in which style or format the response should be given to stated questions or commands of the user.
In our Llama implementation, the instruct chat context will be decoded to the following format:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
System Prompt<|eot_id|>
<|start_header_id|>user<|end_header_id|>
First user message<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
First generated assistant answer.<|eot_id|>
<|start_header_id|>user<|end_header_id|>
Second user message<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>Note: indentation is just for better readability, the actual decoded string does not contain indentations or line breaks
Each message is tagged with a related header specifying the role. The model is supposed to finish it's generated tokens with the end-of-turn-token <|eot_id|>
The instructions can take various forms, such as explicit commands, user feedback, or contextual signals inferred from the conversation.
Hardware Requirements
Although the Llama 3 models were trained on a cluster of H100 80GB GPUs it is possible to run the models on different and smaller multi-GPU hardware for inference.
In table 1 we list a summary of the minimum GPU requirements and recommended AIME systems to run a specific Llama 3 model with realtime reading performance:
| Model | Size | Minimum GPU Configuration | Recommended AIME Server | Recommended AIME Cloud Instance |
|---|---|---|---|---|
| 8B | 15GB | 1x NVIDIA RTX A5000 24GB or 1x NVIDIA RTX 4090 24GB | AIME G400 Workstation or AIME A4000 Server | V10-1XA5000-M6 |
| 70B | 132GB | 2x NVIDIA H100/A100 80GB, 4x NVIDIA RTX A6000/6000 Ada 48GB or 8x NVIDIA RTX A5000 24GB | AIME A4004 Server | V28-2XA180-M6, C24-4X6000ADA-Y1, C32-8XA5000-Y1 |
A detailed performance analysis of different hardware configurations can be found in the section "Llama 3 Inference GPU Benchmarks" of this article.
Our Llama 3 Implementation
Our Llama 3 implementation is a fork of the original Llama 3 repository for Pytorch supporting all current Llama 3 model sizes: 8B and 70B and the Instruct fine tuned versions of the models.
Our fork provides the possibility to convert the weights to be able to run the model on different GPU configurations than the official model weights provided by Meta for Llama 3 (see table 2).
With the integration in our AIME-API and its batch aggregation feature, it is possible to leverage the full possible inference performance of different GPU configurations by aggregating requests to be processed in parallel as batch jobs by the GPUs. This dramaticly increases the achievable throughput of chat requests.
We also benchmarked the different GPU configurations with this technology to guide the decision which hardware gives best throughput performance to process Llama 3 requests.
Try out Llama 3 Chat with AIME API Demonstrator
The AIME-API-Server offers client interfaces for various programming languages. To demonstrate the power of Llama 3 with the AIME API Server, we provide a fully working Llama 3 demonstrator using our Java Script client interface.
Getting Started: How to Deploy Llama 3 Chat
In the following we show how to setup, get the source, download the Llama 3 models, and how to run Llama 3 as console application and as worker for serving HTTPS/HTTP requests.
Create an AIME ML Container
Here are instructions for setting up the environment using the AIME ML container management. Similar results can be achieved by using Conda or alike.
To create a PyTorch 2.1.2 environment for installation, we use the AIME ML container, as described in aime-ml-containers using the following command:
> mlc-create llama3 Pytorch 2.1.2-aime -w=/path/to/your/workspace -d=/destination/of/model/checkpointsThe -d parameter is only necessary if you don’t want to store the checkpoints in your workspace but in a specific data directory. It is mounting the folder /destination/of/model/checkpoints to /data in the container. This folder requires at least 250 GB of free storage to store (all) the Llama 3 models.
Once the container is created, open it with:
> mlc-open llama3You are now working in the ML container being able to install all requirements and necessary pip and apt packages without interfering with the host system.
Clone the Llama3-Chat Repository
Llama3-Chat is a forked version of the original Llama 3 reference implementation by AIME, with the following added features:
- Tool for converting the original model checkpoints to different GPU configurations
- Improved text sampling
- Implemented token-wise text output
- Interactive console chat
- AIME API Server integration
Clone our Llama3-Chat repository with:
[llama3] user@client:/workspace$
> git clone https://github.com/aime-labs/llama3_chatNow install the required pip packages:
[llama3] user@client:/workspace$
> pip install -r /workspace/llama3_chat/requirements.txtDownload Llama 3 Model Checkpoints
In order to download the model weights and tokenizer, you have to apply for access by meta and accept their license. Once your request is approved, you will receive a signed URL via e-mail. Make sure you have wget and md5sum installed in the container:
[llama3] user@client:/workspace$
> sudo apt-get install wget md5sumThen run the download.sh script with:
[llama3] user@client:/workspace$
> /workspace/download.shPass the URL provided when prompted to start the download. Keep in mind that the links expire after 24 hours and a certain amount of downloads. If you start seeing errors such as 403: Forbidden , you can always re-request a link.
The download process might take a while depending on your internet connection speed. For the 70B model 129GB are to be downloaded.
Convert the Checkpoints to your GPU Configuration
The downloaded checkpoints are designed to only work with certain GPU configurations: 8B with 1 GPU and 70B with 8 GPUs. To run the model on a different GPU configuration, we provide a tool to convert the weights respectively. Table 2 shows all supported GPU configs.
| Model size | Num GPUs 24GB | Num GPUs 40GB | Num GPUs 48GB | Num GPUs 80GB |
|---|---|---|---|---|
| 8B | 1 | 1 | 1 | 1 |
| 70B | 8 | 4 | 4 | 2 |
The converting can be started with:
[llama3] user@client:/workspace$
> python3 /workspace/llama3_chat/convert_weights.py --input_dir /data/models/Meta-Llama-3-70B-Instruct/ --model_size 70B --num_gpus <num_gpus>The converting will take some minutes depending on CPU and storage speed and model size.
Run Llama 3 as Interactive Chat in the Terminal
To try the Llama 3 models as a chat bot in the terminal, use the following PyTorch script and specify the desired model size to use:
[llama3] user@client:/workspace$
> torchrun --nproc_per_node <num_gpus> /workspace/llama3_chat/chat.py --ckpt_dir /data/models/Meta-Llama-3-70B-InstructThe chat mode is simply initiated by giving the following context as the starting prompt. It sets the environment so that the language model tries to complete the text as a chat dialog:
A dialog, where User interacts with a helpful, kind, obedient, honest and very reasonable assistant called Steve.
User: Hello, Steve
Steve: How can I assist you today?
Now the model acts as a simple chat bot. The starting prompt influences the mood of the chat answers. In this case, he credibly fills the role of a helpful assistant and does not leave it again without further ado. Interesting, funny to useful answers emerge - depending on the input texts.
Run Llama 3 Chat as Service with the AIME API Server
Setup AIME API Server
To read about how to setup and start the AIME API Server please see the setup section in the documentation.
Start Llama 3 as API Worker
To connect the LLama3-chat model with the AIME-API-Server ready to receive chat requests through the JSON HTTPS/HTTP interface, simply add the flag --api_server followed by the address of the AIME API Server to connect to:
[llama3] user@client:/workspace$
> torchrun --nproc_per_node <num_gpus> /workspace/llama3_chat/chat.py --ckpt_dir /data/models/Meta-Llama-3-70B-Instruct/ --api_server https://api.aime.info/3
Now the LLama 3 model acts as a worker instance for the AIME API Server ready to process jobs ordered by clients of the AIME API Server.
For a documentation on how to send client requests to the AIME API Server please read on here.
Llama 3 Inference GPU Benchmarks
To measure the performance of your LLaMA 3 worker connected to the AIME API Server, we developed a benchmark tool as part of our AIME API Server to simulate and stress the server with the desired amount of chat requests. First install the requirements with:
user@client:/workspace/aime-api-server/$
> pip install -r requirements_api_benchmark.txtThen the benchmark tool can be started with:
user@client:/workspace/aime-api-server/$
> python3 run_api_benchmark.py --api_server https://api.aime.info/ --total_requests <number_of_requests>run_api_benchmark.py will send as many requests as possible in parallel and up to <number_of_requests> chat requests to the API server. Each requests starts with the initial context "Once upon a time". Llama 3 will generate, depending on the used model size, a story of about 400 to 1000 tokens length. The processed tokens per second are measured and averaged over all processed requests.
Results
We show the results of the different Llama 3 model sizes and GPU configurations. The model is loaded in such a way that it can use the GPUs in batch mode. In the bar charts the maximum possible batch size, which equals the parallel processable chat sessions, is stated below the GPU model and is directly related to the available GPU memory.
The results are shown as total possible throughput in tokens per second and the smaler bar shows the tokens per second for an individual chat session.
The human (silent) reading speed is about 5 to 8 words per second. With a ratio of 0.75 words per token, it is comparable to a required text generation speed of about 6 to 11 tokens per second to be experienced as not to slow.
Llama 3 8B GPU Performance
Llama 3 70B GPU Performance
Conclusion
Integrating Llama 3 with AIME API and its straightforward setup offers developers a scalable solution for deploying conversational AI solutions. By utilizing Llama 3 alongside the AIME API Server, developers can create advanced applications like chatbots, virtual assistants, and interactive customer support systems.
The hardware requirements for running Llama 3 models are flexible, allowing for deployment on various distributed GPU configurations and extendable setups or infrastructure to serve thousands of requests. Even the minimum GPU requirements or smallest recommended AIME systems for each model size ensure a more than real-time reading response performance for a seamless multi-user chat experience.




