Es gibt verschiedene Ansätze, um die Benutzererfahrung bei der Arbeit mit Stable Diffusion für die KI-basierte Bilderzeugung zu verbessern. Zwei dieser Ansätze haben sich bislang durchgesetzt: die AUTOMATIC1111 webUI und Invoke-AI. Beide Ansätze erleichtern die textbasierte Bilderzeugung (txt2image) auf unterschiedliche Weise. In diesem Artikel wird die webUI von AUTOMATIC1111 als eine benutzerfreundliche und bequeme Möglichkeit vorgestellt, Stable Diffusion zu nutzen.
webUI von AUTOMATIC1111 ist ein Open-Source-Projekt, das die Verwendung des generativen Bilderzeugungsmodelles Stable Diffusion erleichtert und um zusätzliche Funktionen erweitert. Für diejenigen, die eine bequeme und benutzerfreundliche Option suchen, um mit Stable Diffusion zu arbeiten, ist die webUI daher eine ausgezeichnete Wahl. Im Folgenden wird erläutert, wie man die webUI bequem mittels AIME MLC installieren und verwenden kann.
Die Nutzung der webUI bietet gegenüber der Verwendung der Kommandozeile, wie im vorherigen Blogartikel beschrieben, insbesondere für Anfänger einen deutlichen Vorteil, da Einrichtung und Bedienung sehr einfach sind. Die intuitive Weboberfläche ermöglicht den einfachen Zugriff auf alle Funktionen und es werden stetig neue hinzugefügt. Zudem ist die Bedienung der webUI effizienter als die Befehlszeile. Um mit der Nutzung der webUI zu beginnen, muss man lediglich einen AIME MLC-Container erstellen und den unten beschriebenen Installationsanweisungen folgen.
Die webUI-Benutzeroberfläche bietet viele durch Registerkarten getrennte Bereiche mit verschiedenen Optionen zur Erstellung und Bearbeitung von Bildern. Im Folgenden werden die Funktionen der einzelnen Registerkarten der webUI kurz erläutert. Zudem werden die verschiedenen Versionen von Stable Diffusion in Beispielen verglichen. Abschließend finden sich Tipps und Tricks zur Optimierung der Qualität der generierten Bilder.
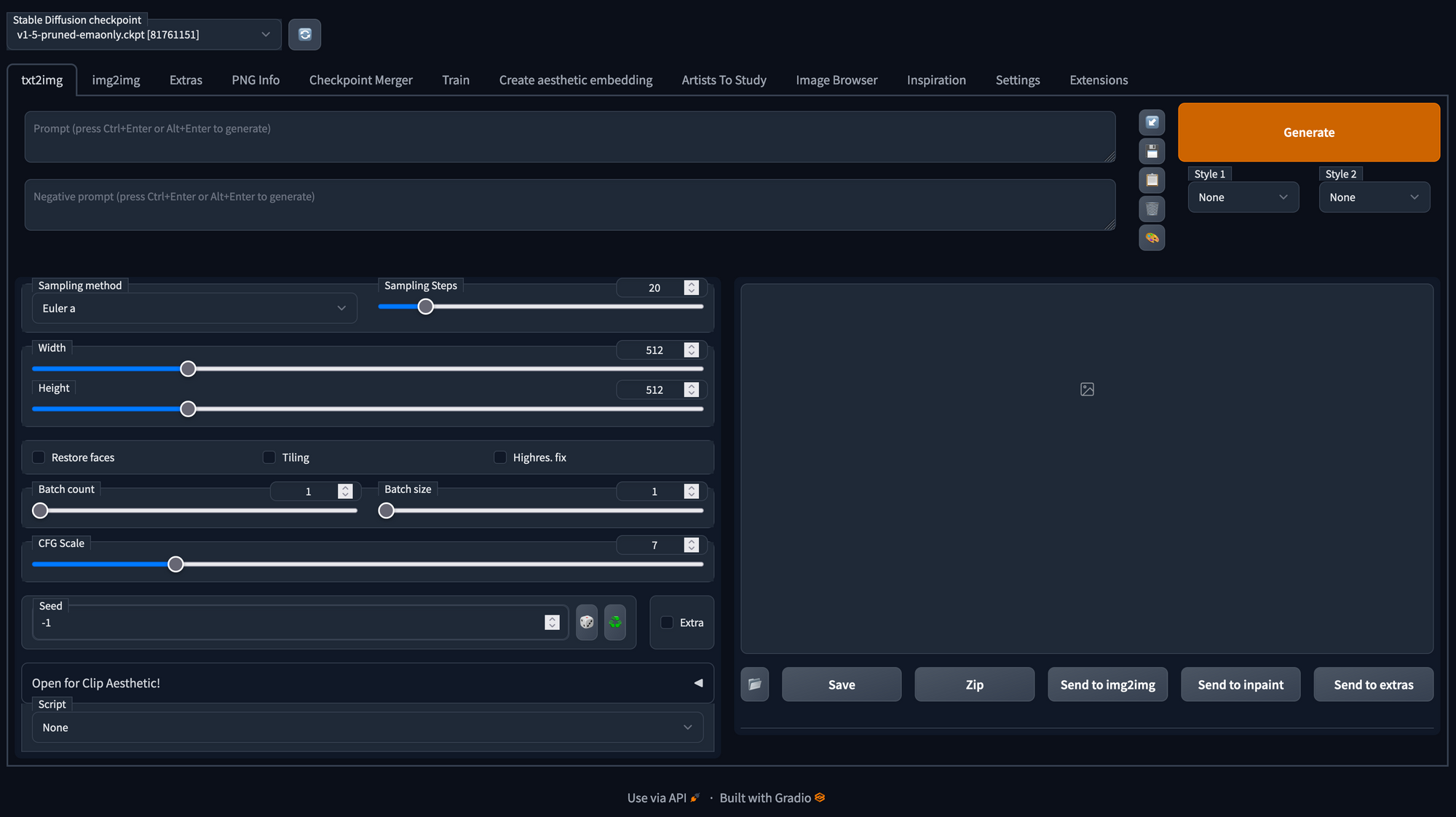
Installation
Um webUI zu installieren, ist der erste Schritt die Erstellung eines Arbeitsverzeichnisses mit dem Namen "stable-diffusion-webui", das Klonen des Github-Repositorys und die Erstellung eines AIME-ML-Containers. Falls der Pytorch 1.13.1 Container noch nicht verfügbar ist, muss MLC vorab aktualisiert werden.
mkdir stable-diffusion-webui
cd stable-diffusion-webui/
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
mlc-update-sys
mlc-create webui-automatic1111 Pytorch 1.13.1 -w=./stable-diffusion-webui/
mlc-open webui-automatic1111Vor dem Start der Konfiguration müssen einige Änderungen vorgenommen werden, wie die Installation und Aktualisierung von Paketen und Abhängigkeiten:
[webui-automatic1111] user@hostname:/workspace$
sudo apt update && sudo apt-get install libgl1 wget unzip libglib2.0-0 python3.8-venv nano
pip install fastapiDa AIME MLC selbst bereits eine virtuelle Umgebung darstellt, in der sowohl GPU-Treiber, als auch CUDA, PyTorch etc. vorinstalliert sind, ist es nicht nötig, eine weitere virtuelle Umgebung, wie z.B. venv oder conda zu erstellen. Da dies im Auto-Installationsskript von webUI nicht berücksichtigt wird, muss es entsprechend angepasst werden. Dazu muss die Datei webui-user.sh bearbeitet werden, indem die Zeile, die die virtuelle Umgebung adressiert, auskommentiert wird. Durch die Änderung von "venv" in "-" wird verhindert, dass eine neue Umgebung in einem Ordner namens "venv" erstellt wird. Es wird nun lediglich ein Ordner namens "-" erstellt, den wir im Weiteren ignorieren.
> sudo nano webui-user.sh
line 22: venv_dir = "venv"
-> change to: venv_dir = -
Nun müssen die Modelldateien (Gewichte) heruntergeladen und installiert werden:
[webui-automatic1111] user@hostname:/workspace$
cd models/Stable-diffusion/
wget --no-parent -nd --accept *.zip -r http://download.aime.info/public/models
unzip -j -o "*.zip"
rm *.zip
cd -
Die Modelldateien der Versionen 1.5 und 2.1 werden in das Verzeichnis models/Stable-Diffusion/ installiert. Diese Modelle unterliegen der CreativeML OpenRAIL M-Lizenz.
Die webUI ermöglicht durch Klick auf die graublaue Aktualisierungs-Button neben dem Checkpoint-Selektor einen schnellen Wechsel zwischen den verschiedenen Modell-Versionen:

Das webui.sh-Skript erledigt nun den Rest der Installation. Obwohl nicht verwendet, wird die venv-Umgebung aus Gründen der Einfachheit mit installiert, da das Installationsskript dessen Vorhandensein überprüft. Um später Aktualisierungen der webUI problemlos installieren zu können, ohne das Skript jedes Mal neu bearbeiten zu müssen, belassen wir es, wie es ist.
Da sich die webUI in einer aktiven Entwicklungsphase befindet und es täglich umfangreiche Änderungen geben kann, wird in dieser Beschreibung auf den Git Commit #22bcc7be428c94e9408f589966c2040187245d81 (vom 30. März 2023) verwiesen. Es wird empfohlen, den Branch zu wechseln, wenn beim ersten Start des webUI-Servers Probleme mit dem aktuellen Entwicklungsstand auftreten.
git checkout ea9bd9fc7409109adcd61b897abc2c8881161256Ausführen der AUTOMATIC1111 webUI
Zuletzt wird die webUI gestartet und damit eine Installationsroutine in Gang setzt, die das Vorhandensein aller Abhängigkeiten prüft, bevor sie den webUI-Server startet. Es wird empfohlen, die xformers-Bibliothek zu verwenden, die ein leistungsfähiges Werkzeug ist, um die Bilderzeugung zu beschleunigen und den Speicherbedarf der GPU zu verringern. Fügen Sie das Argument --xformers hinzu, um diese zu verwenden:
bash webui.sh --xformersNun lassen sich Bilder generieren, indem ein Prompt in das entsprechende Textfeld eingegeben und durch den Button "Generieren" ausgelöst wird. Es lassen sich außerdem negative Prompts verwenden und die Parameter anpassen, wie sie in unserem vorherigen Blogartikel zu Stable Diffusion beschrieben werden.
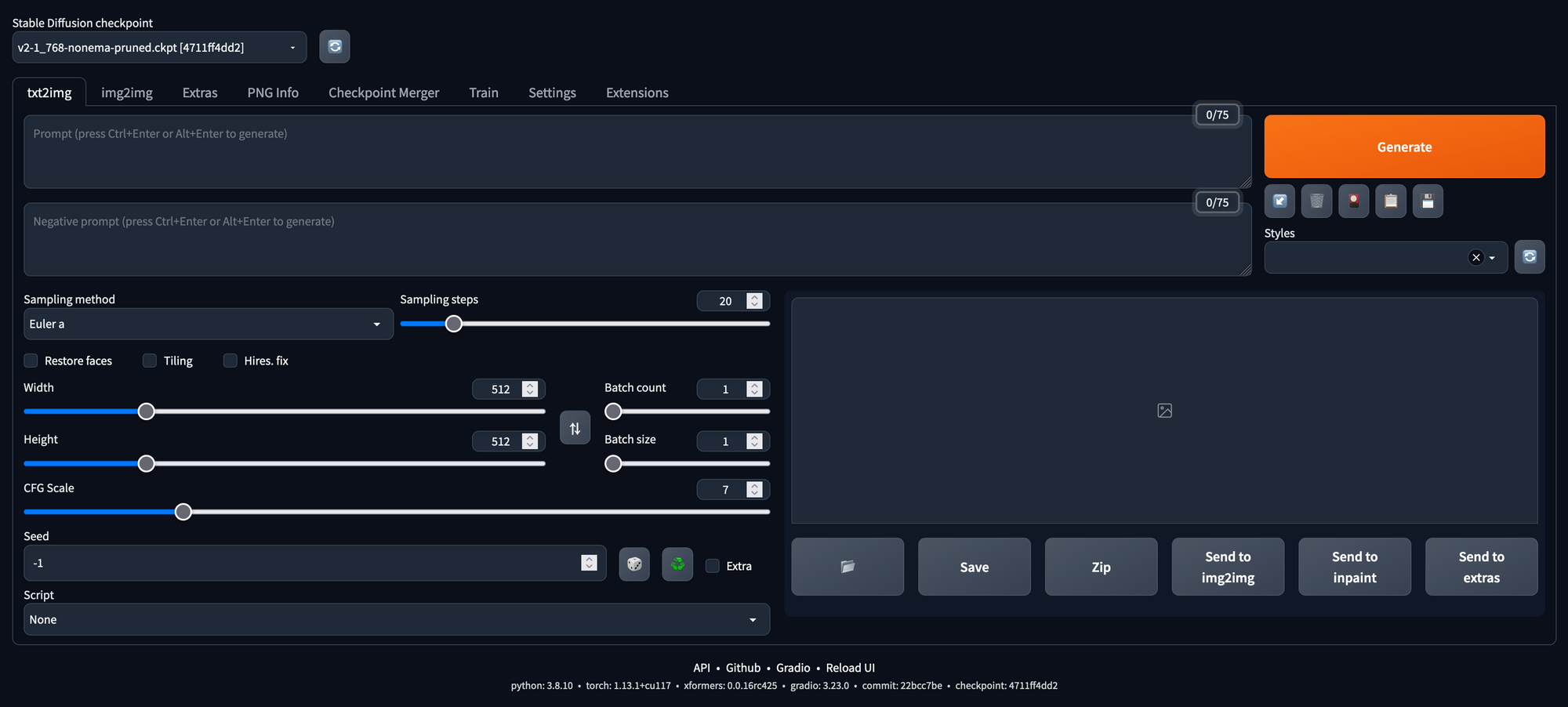
Stable Diffusion V1 vs. V2
Die Architektur von Stable Diffusion V2 unterscheidet sich ein wenig von der vorherigen Version Stable Diffusion V1.
Die wichtigste Änderung, die Stable Diffusion 2 vornimmt, ist das Ersetzen des Text-Encoders. Stable Diffusion 1 verwendete OpenAIs CLIP, um eine Beschreibung von Bildern während des Trainings zu erhalten. Der Datensatz, auf dem CLIP trainiert wurde, ist Closed Source. Stable Diffusion 2 verwendet nun OpenCLIP, das quelloffen ist und auf einem öffentlich bekannten Datensatz trainiert wurde, der eine gefilterte Teilmenge von LAION-5B darstellt.
Es wird behauptet, dass die neue Version Bilder von schlechterer Qualität erzeugt, weil nur eine Teilmenge des LAION-5B-Datensatz verwendet wurde, aus dem urheberrechtlich geschützte Bilder herausgefiltert wurden. Infolgedessen können viele bekannte Künstlernamen im Prompt für die Bilderzeugung nicht verwendet werden, um ihren Stil auf neu generierte Bilder zu übertragen. Das V2-Modell hat jedoch ein besseres Gespür für die Wortpositionen und kann mit längeren, komplexeren Aufforderungen umgehen. Es reagiert auch besser auf eine höhere CFG-Skala und fügt den generierten Bildern mehr Details hinzu. Ein Grund hierfür ist der neu trainierte OpenCLIP-Encoder, der den Prompt-Text in Embeddings kodiert.
Vergleicht man V1.5 und V2.1, so zeigt sich, dass V2 den Kontext besser erfasst und die Beschreibung besser trifft. Sie ist besonders gut in der Lage, Bilder von Landschaften, Architektur, Design und Tierlebensräumen zu erzeugen. Auch die Fähigkeit, Bilder der menschlichen Anatomie, einschließlich Gliedmaßen und Hände, zu erzeugen, wurde verbessert. V2.0 hatte jedoch aufgrund der auf den Datensatz angewendeten Filter Probleme mit Kunststilen und Prominenten. V2.1 wurde auf dem V2.0-Modell mit einem niedrigeren Filter abgestimmt und schneidet in dieser Hinsicht besser ab - aber immer noch nicht so gut wie V1.5.
Neben dem Basismodell enthält V2 auch mehrere Spezialmodelle:
- 512x512 txt2img
Dieses Modell ist darauf trainiert, 512x512 Bilder zu erzeugen, genau wie die vorherigen V1-Modelle. Es enthält sowohl ein Basismodell als auch ein Ema-Modell. - 768x768 txt2img
Dieses Modell ist für die Erzeugung von 768x768 Bildern trainiert. - depth2img
Dieses Modell ist ein separates img2img-Modell, das die vorherige Version durch die Erstellung einer Tiefenmaske verbessert. Dadurch wird den erzeugten Bildern ein Gefühl von Tiefe verliehen. - Superresolution upscaler x4
Dieses Modell ist darauf trainiert, die Auflösung der erzeugten Bilder durch Hochskalierung zu verbessern. - Inpainting
Dieses Modell ist ein verbessertes Inpainting-Modell.
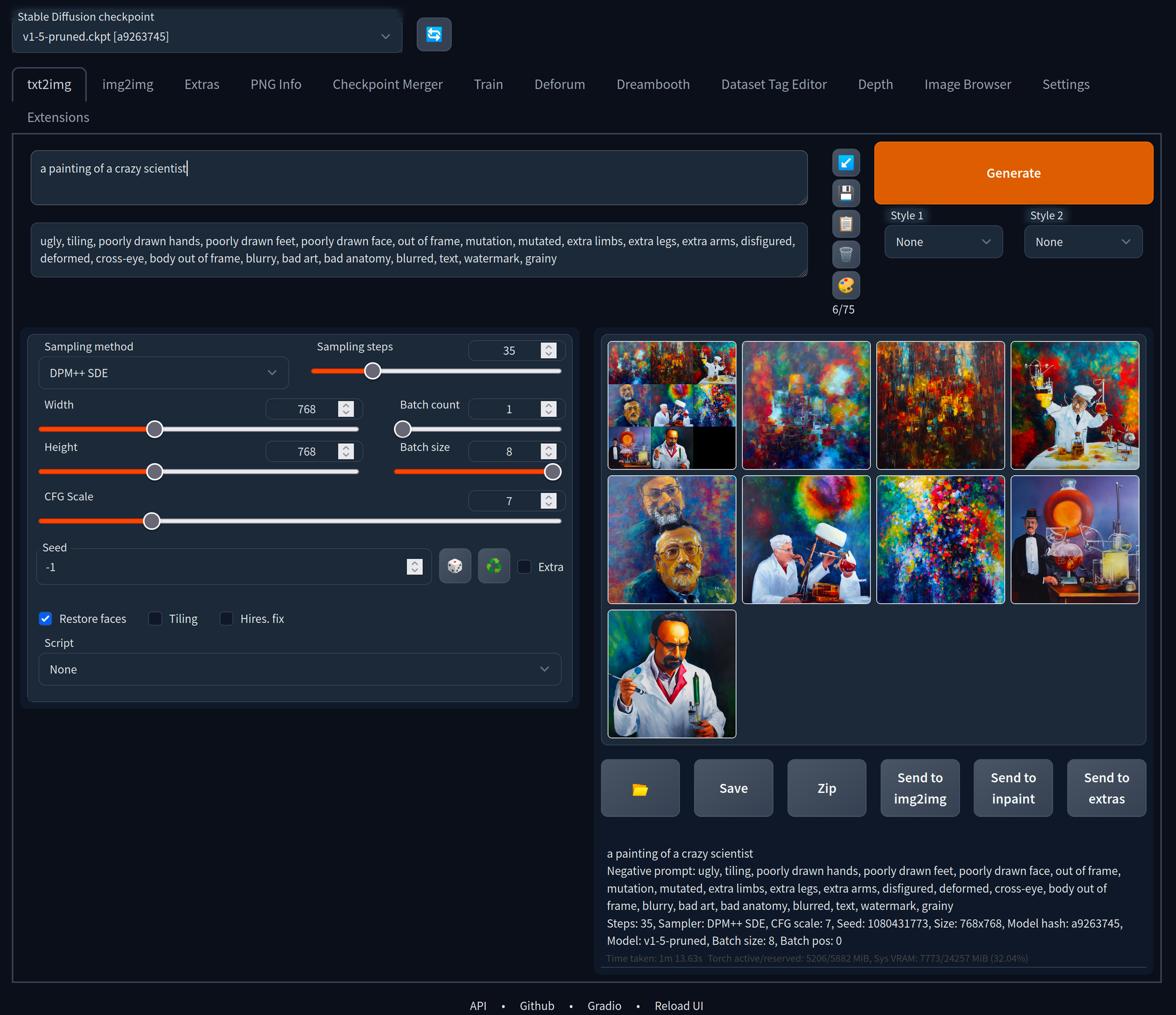
In diesem Artikel werden die Modelle V2.1 768x768 und V1. 5 512x512 verglichen, wobei die verschiedenen Funktionen der webUI beschrieben werden.
AUTOMATIC1111 WebUI
In den nächsten Abschnitten werden die wichtigsten Funktionen der einzelnen Registerkarten der webUI kurz vorgestellt. Das Github Repo wird regelmäßig mit neuen Funktionen aktualisiert. Bei Fragen oder Problemen gibt es auch einen hervorragenden Support.
Das Feature-Wiki ist eine exzellente und umfassende Darstellung aller Funktionen, zusammen mit Erklärungen und Beispielen. Es erklärt die Verwendung der Schnittstelle und interessante Funktionen wie:
- Textual Inversion
- Lora
- Hypernetworks
- Depth Guided Model
- Inpainting/Outpainting
- Masking
- Prompt matrix
- Upscaling/Resizing
- Infinite prompt length/BREAK keyword
- Attention/emphasis
- Loopback
- X/Y/Z plot
- Styles
- negative prompts
- CLIP interrogator
- Face restoration
und viele weitere.
Vielen Dank an den Ersteller AUTOMATIC1111 und die Mitwirkenden, die das Github-Repo aktuell halten und stetig verbessern.
webUI Features
Im Folgenden werden einige der Funktionen und Registerkarten der webUI beschrieben.

Txt2Img Tab
Dies ist die klassische Text-zu-Bild-Generierung. Prompt und Parameter werden auf der linken Seite eingegeben, die Ausgaben wird auf der rechten Seite erzeugt. Die Funktionalität gleicht der wie im vorherigen Blog-Artikel beschriebenen, bietet aber mehr Optionen und ist bequemer in der Anwendung. Eine ausführliche Anleitung zum Prompting findet sich im benannten Artikel oder im Stable Diffusion v1 Prompt Book.
Prompt Features
- Nach Eingabe des Prompts startet ein Klick auf den "Generate"-Button die Bilderzeugung. Der Button interrupt unterbricht den Vorgang. Um die Generierung auf unbestimmte Zeit laufen zu lassen, klickt man mit der rechten Maustaste auf den Generieren-Button und wählt Generate forever. interrupt beendet diesen Vorgang.
- Negative Prompt
Hier beschreibt man, was nicht generiert werden soll. Dies ist besonders nützlich für die Feinabstimmung, sobald ein geeignetes Bild gefunden wurde. Hierdurch lassen sich z.B. zusätzliche Gliedmaßen entfernen oder schlecht gezeichnete Hände, Füße oder Gesichter vermeiden.- Eine gängige Negativ-Eingabeaufforderung für Menschen lautet "ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, blurred, text, watermark, grainy.". Diese Eingabeaufforderung kann als Stil gespeichert und immer dann verwendet werden, wenn eine Feinabstimmung des Modells vorgenommen werden soll.


Negative prompt: "black clothing, poorly drawn hands, poorly drawn face, disfigured, disconnected limbs, bad anatomy, deformed, cross-eye, blurry, bad art, bad hands"
Steps: 20
Sampler: DPM++ SDE
CFG scale: 9.5
Seed: 3574490288
Size: 768x768
Model: v2-1_768-ema-pruned.ckpt
- Styles
Dies ist eine weitere einfache Funktion zur Verbesserung des Arbeitsablaufs. Eingabeaufforderungen lassen sich als Stil für die wiederholte Verwendung speichern, z.B. Magic Words, um Bilder zu optimieren. Es lassen sich Prompts und Negative Prompts als Stil speichern.

- Prompt Scheduling
Ermöglicht das Umschalten der Eingabeaufforderung während des Samplings:[word1: word2 : x], um den Prompt in Schritten oder Bruchteilen von 0 < x < 1 zwischen wort1 zu wort2 zu mischen. Zum Beispiel mischt der Prompt a picture of a [Christmas: old oak: 0.5] tree das Bild eines Weihnachtsbaums zu 50% mit dem einer alten Eiche. Bei der Hälfte der Schritte des Samplers wird hierfür von dem Bild eines Weihnachtsbaums zum Bild einer alten Eiche gewechselt.


- Weight or Attention/Emphasis
Die Gewichtung eines Wortes im Prompt lässt sich mit der Syntax(word: factor)festlegen, wobei Faktor ein Float-Wert größer als Null ist. Ein Wert kleiner als 1 bedeutet weniger wichtig, während Werte größer als 1 wichtiger bedeutet. Zum Beispiel können wir die Gewichtung des Schlüsselworts dog im folgenden Prompt anpassen: "man and (dog: 1.8) in the streets of new york, beautiful, atmosphere, vibe, rain, wet ".
Derselbe Effekt lässt sich mit Klammern wie (word) zur Abschwächung von Wörtern und [word] zur Abschwächung von Wörtern erzielen. Es lassen sich mehrere Instanzen verwenden, um den Effekt zu verstärken, z.B.: "man and [[dog]] in the streets of new york". Es gibt algebraische Regeln, die besagen, das (Wort) die Stärke des Schlüsselworts um den Faktor 1,1 erhöht, was die gleiche Wirkung hat wie (Wort:1,1). [Wort] verringert die Stärke um den Faktor 0,9, wie bei (Wort:0,9). Die Wirkung ist multiplikativ wie bei ((Wort)): 1,21, (((Wort)))): 1,33 und [[Wort]]: 0.81, [[[Wort]]]: 0,73.
Eine weitere Möglichkeit, die Gewichtung von Wörtern zu verstärken, besteht darin, sie weiter vorne zu platzieren.


Parameter und Optionen
Die folgenden Parameter werden im vorherigen Blog-Artikel genauer erläutert.
- Sampler und Steps
Es stehen verschiedene Sampler zur Auswahl, die im vorherigen Blogartikel erläutert werden. Je mehr Sampling-Schritte, desto länger dauert die Bilderzeugung. Ein guter Einstieg ist die Verwendung des DPM++ 2M Samplers mit 20 Samplingschritten. - Dimensions
Höhe und Breite, am besten auf das Standardmaß des Modells einstellen. - Batch Count und Size
Anzahl der zu erzeugenden Bilder. - CFG scale: Guidance-Skala
- Seed: -1 für Zufallswert-Erzeugung
- Tiling support
UI-Kontrollkästchen, um Bilder zu erstellen, die wie Texturen gekachelt werden können. Die Kachelgröße kann nach Bedarf angepasst werden. - Restore faces
Hier wird das Generative Facial Prior GAN (GFPGAN) verwendet, um Gesichter zu korrigieren, z. B. durch Beibehaltung der Symmetrie und Wiederherstellung des Aussehens eines zusammengefallenen Gesichts. - Highres fix
Erzeugen Sie hochauflösende Bilder ohne die üblichen Verzerrungen, wie Wiederholungen. Es handelt sich um einen zweistufigen Prozess, bei dem zunächst Bilder mit einer geringeren Auflösung erstellt und dann auf eine höhere Auflösung hochskaliert werden.

Negative prompt: "bee hat",
Steps: 20,
Sampler: DPM++ SDE,
CFG scale: 12.5,
Seed: 3239510979
Skripte
Dies ist eines der wichtigsten Features, da sie den Arbeitsablauf in der Experimentierphase für verschiedene Prompts und Seeds beschleunigt und die Parametrisierung in der Feinabstimmungsphase erleichtert:
- X/Y grid
Wählt man verschiedene Sampler oder CFG-Skalen als Parameter, wird ein Raster mit allen Kombinationen erstellt.
x0 - x1 [iter], ex 0.0 - 1.0 [10] or +(x_t)
- Prompt S/R
Zu finden in den X/Y-Skriptoptionen. S/R steht für Suchen/Ersetzen. Es sucht nach dem ersten Wort und ersetzt es durch die Wörter in der Liste.- Prompt: 'a picture of a dog'
- S/R-Prompt: 'a dog, a cat, a wild elephant'
- Ergebnis: ein Bild von einem Hund, ein Bild von einer Katze, ein Bild von einem wilden Elefanten

- Prompt Matrix
Hier lassen sich verschiedene (Teile von) Prompts kombinieren. Dazu gibt man Wörter, die integriert werden sollen, am Ende des Prompts ein, in der Form | string0 \ string1\ string2.

Negative prompt: "white borders",
Steps: 30,
Sampler: DPM++ 2M,
CFG scale: 8.5,
Seed: 21391486.0,
Size: 768x768,
Model: v2-1_768-ema-pruned.ckpt.
- Prompt for file or textbox
Erzeugt mehrere Prompts, wobei jeder Prompt in einer neuen Zeile steht.
Ausgaben
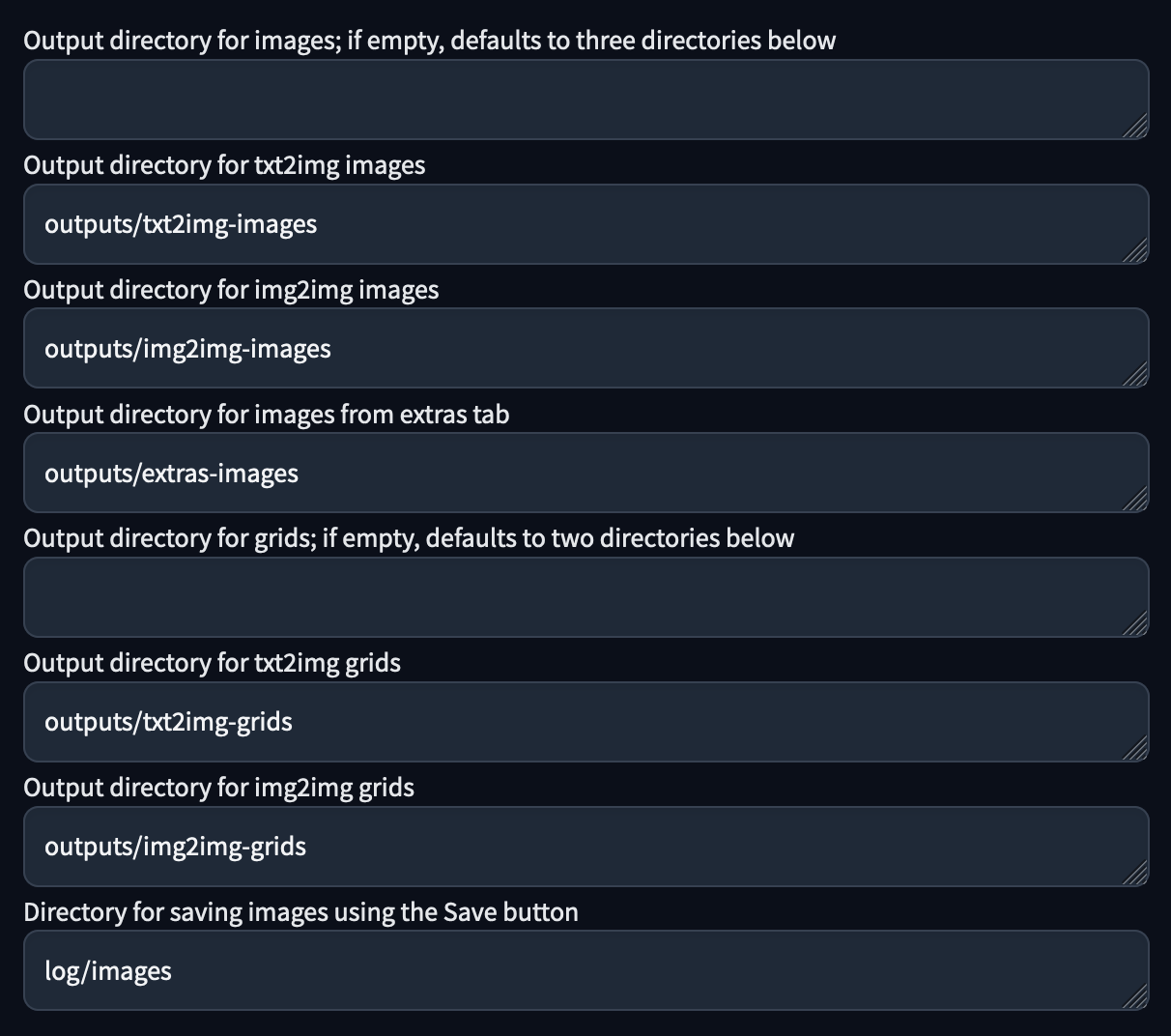
Alle Ausgaben werden im Ordner outputs/txt2img-images oder txt2img-grids gespeichert. txt2img-grids listet die Bilder auf, wenn mehrere auf einmal erzeugt werden. Der Namen des/der Ordner(s) kann auf der Registerkarte "Settings" unter Path for saving bearbeitet werden.
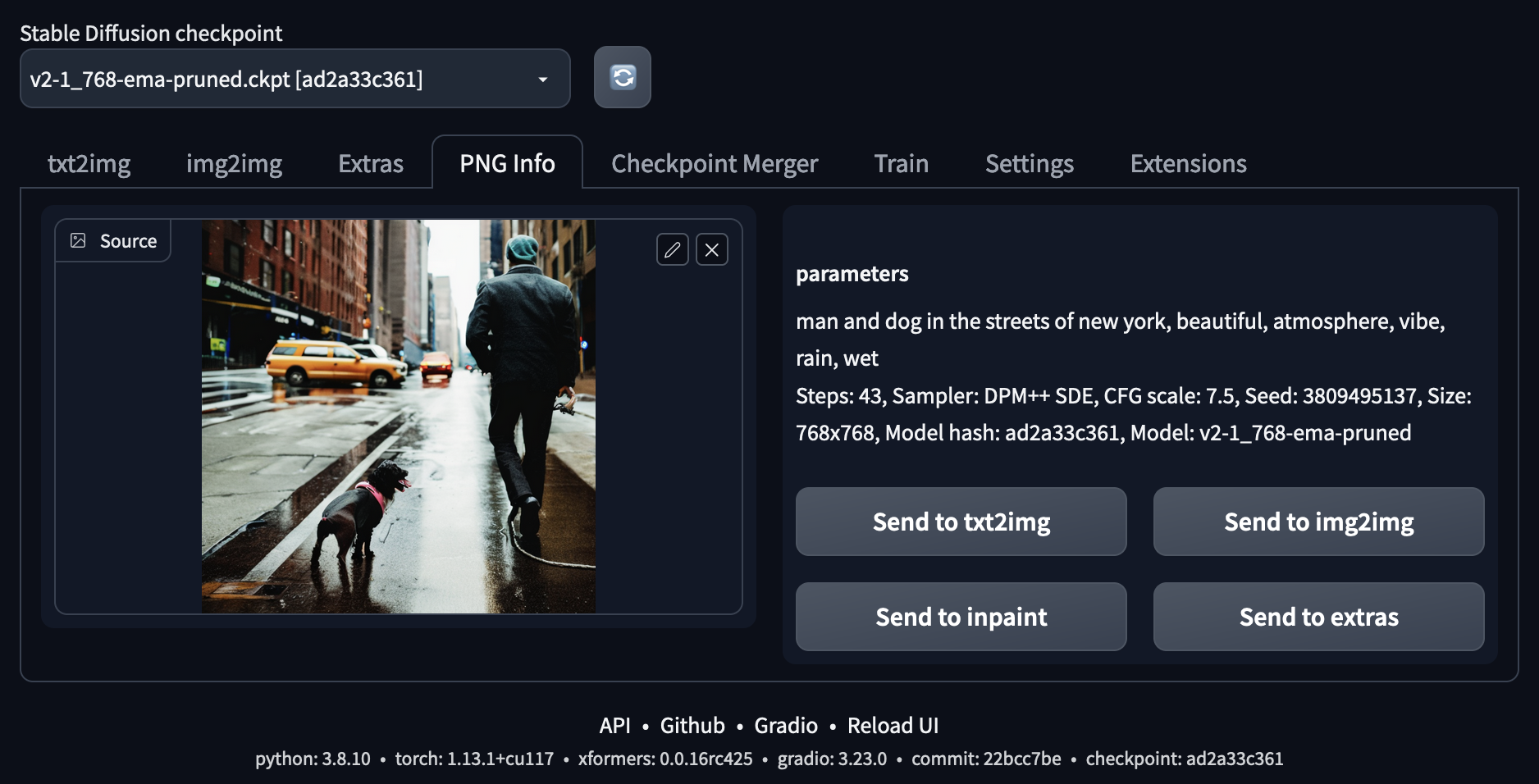
Zwischen den Tabs/Registerkarten besteht die Möglichkeit, die Bildausgabe an andere Registerkarten zu senden. Dies ermöglichen entsprechend benannte Buttons unter der Bildausgabe. Die Metadaten der Bilder werden unter den erzeugten Bildern angezeigt und im Ausgabebild gespeichert. Sie können mit dem Metadatenleser auf der Registerkarte "PNG-Info" ausgelesen werden.
Es gibt auch gute Erweiterungen zum Durchsuchen eines Bildverlaufs, mehr dazu weiter unten.
Img2Img
Mit der Registerkarte Img2Img können Bilder sowohl auf der Grundlage eines Prompts als auch eines Eingabebildes erzeugt werden. Dies bietet eine breite Palette von Möglichkeiten.
Interrogate CLIP
CLIP ist der Text-Encoder, der die Prompts in Embeddings umwandelt. Das Anklicken von Interrogate CLIP löst den umgekehrten Weg aus: Das CLIP-Modell interpretiert dann den Inhalt des Bildes und gibt eine Textbeschreibung aus. Es ist zu beachten, dass dies nicht genau die Eingabeaufforderung wiedergibt, die zur Bilderzeugung genutzt wurde, sondern einer Interpretation des CLIP-Modells entspricht.
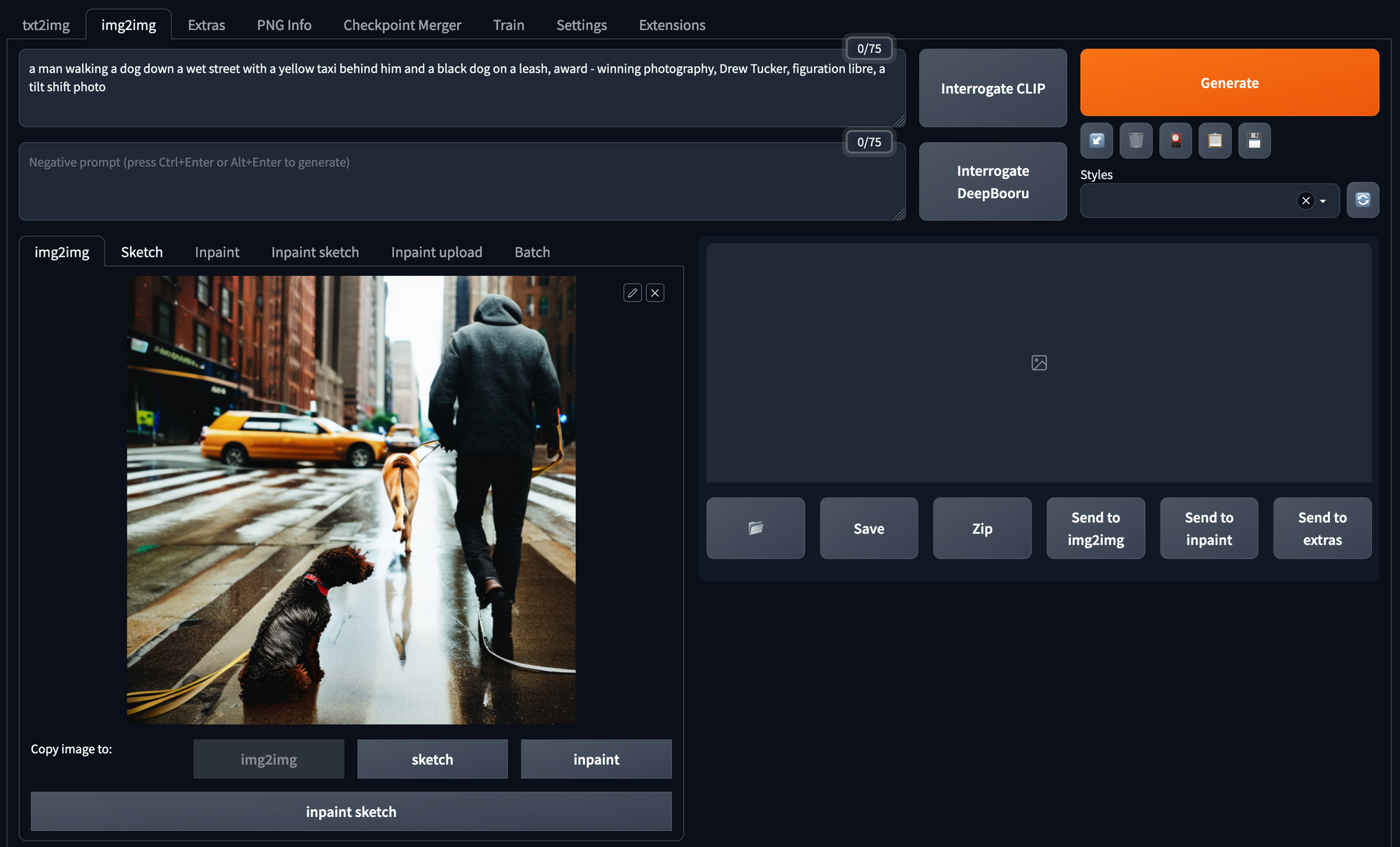
Img2Img
Dies erzeugt ein Bild aus der Kombination eines Prompts und eines Eingabebildes. Der Prompt sollte die Eingabe und die zu ändernden Aspekte des Eingabebildes beschreiben. Es lassen sich die gleichen Parametereinstellungen vornehmen wie in der Registerkarte txt2img.
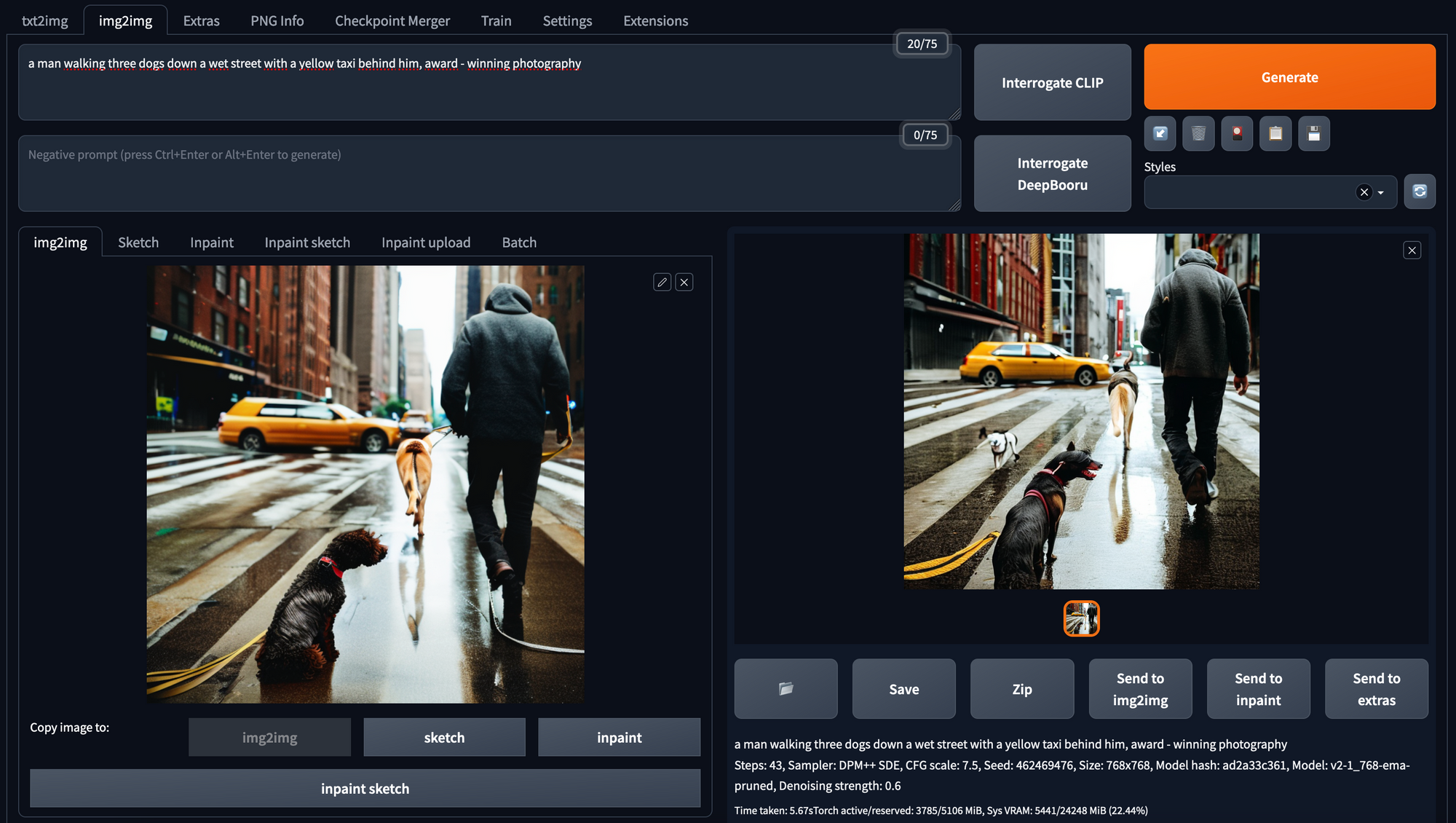
Einer der zusätzlichen Parameter ist die Stärke der Entrauschung (denoising strength). Dabei handelt es sich um eine Orientierungsskala, die angibt, wie viel des zugrunde liegenden Originalbildes im neuen Bild verwendet wird. Ein guter Anfang für diesen Parameter liegt zwischen 0,6 und 0,7.

Steps: 20,
Sampler: Euler a,
CFG scale: 11.5,
Seed: 470802332,
Size: 768x768,
Model: v2-1_768-ema-pruned.ckpt.
Ein paar weitere Anwendungsbeispiele für img2img sind:
- Verwandeln einer Skizze in schöne Kunst. Eine weitere interessante Option ist es, eine Skizze mit dem Farbskizzen-Werkzeug zu erstellen. Hierzu fügt man --gradio-img2img-tool color sketch in das Befehlszeilenargument hinzu.
- Mit Restore faces, lassen sich Gesichter wiederherstellen.
- Es lassen sich auch Variationen eines generierten Bildes erstellen. Hierbei ist darauf zu achten, dieselbe Eingabeaufforderung zu verwenden, wenn man ähnliche Bilder möchte oder kleine Aspekte im Prompt zu ändern. Dies ist ein nützliches Werkzeug für die Feinabstimmung.

Steps: 29
Sampler: DPM++ 2M
CFG scale: 10
Seed: 103025262
Denoising strength: 0.66
Conditional mask weight: 1.0
- img2img alternative test
hiermit lassen sich kleine Aspekte eines Bildes von einem Gesicht ändern. Dies lässt sich gut mit der Skript-Option kombinieren. Dieses Video und dieser Link zur Anleitung enthalten weitere Informationen und Anleitungen.
Inpainting
Bildinhalte lassen sich mittels Masken gezielt übermalen oder um neue Inhalte erweitern. Hierzu zeichnet man eine Maske oder lädt sie hoch, um den Bereich zu definieren, der übermalt oder erweitert werden soll. Der Prompt wird dann verwendet, um den Inhalt zu beschreiben, der in diesem Bereich platziert werden soll. Das Modell muss hierfür auf ein Inpainting-Modell geändert werden. Es können mehrere Parameter eingestellt werden, um den Übermalungsprozess zu steuern.
- Mask blur
- Masked content options: entscheidet, was in dem maskierten Bereich platziert wird, bevor die Aufforderung angewendet wird
- Original content: dies ist der Ausgangspunkt.
- Fill: löscht den Inhalt der Maske und regeneriert das Bild entsprechend
- Latent noise: man startet mit statischem Rauschen
- Latent nothing: von Null anfangen
- At full resolution: während des Erstellungsprozesses in den maskierten Bereich zoomen. Dies ist zu empfehlen.
- Denoising: um die Qualität des erzeugten Bildes zu verbessern empfiehlt es sich, hiermit zu experimentieren.
- Um verschiedene Farben für die Maske zu verwenden, aktivieren Sie
--gradio-inpaint-tool color-sketchals Kommandozeilenargument.
Ein gutes Anwendungsbeispiel für das Inpainting ist das Ändern kleiner Teile eines Bildes, z. B. der Augen oder des Mundes in einem Gesicht: Man deckt nur den Teil ab, den man ändern möchten (wie den Kopf in dem Beispiel der Motorad-Ratte unten), und setzt die Entrauschungsstärke (denoising) auf 0,5. Für menschliche Gesichter aktiviert man die Option 'Gesichter wiederherstellen' (restore faces). Nun verwednet man den original-Prompt wie bei der erstellung des Originalbildes und generiert verschiedene Beispiele.

Prompt: "a drawing of a smiling rat, vivid colors"
Steps: 29,
Sampler: DPM++ 2M,
CFG scale: 10,
Seed: 103025262,
Size: 512x512,
Model: 512-inpainting-ema.ckpt,
Denoising strength: 0.66,
Conditional mask weight: 1.0,
Mask blur: 4
Extras
Upscaling
Zum Hochskalieren, also der Verbesserung der Auflösung von Bildern mit geringen Abmessungen, wie 512x512, bietet sich der ESPRGAN_4X Upscaler in der Registerkarte 'Extras' an. Hiermit lässt sich die Auflösung erhöhen, ohne zu viele Details zu verlieren.
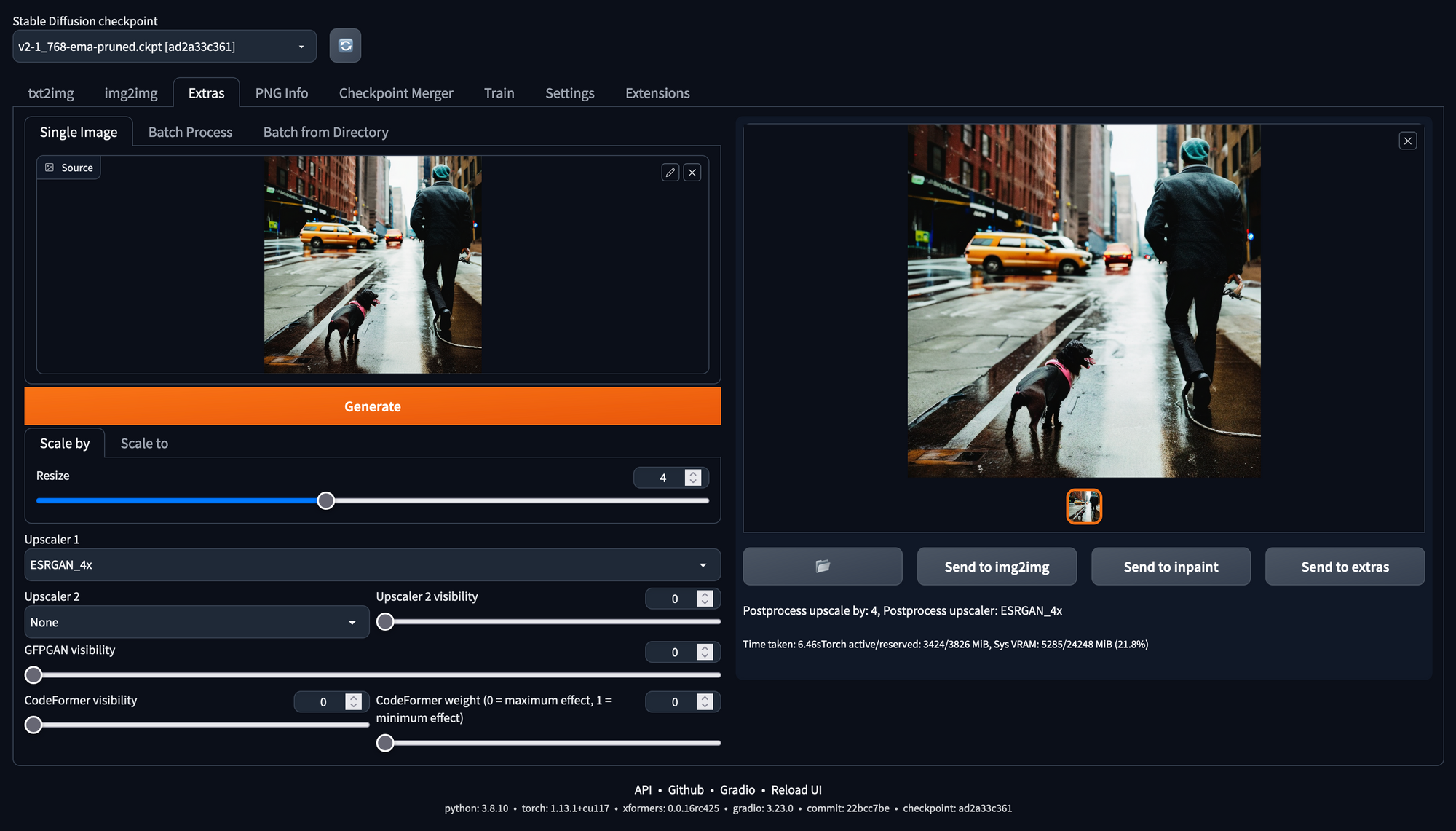
Zusätzlich zur Hochskalierung stellen die Werkzeuge GFPGAN und CodeFormer verzerrte oder beschädigte Flächen in Bildern wieder her. Sie können einzeln oder in Kombination verwendet werden. Ein guter Anfang ist es, den Schieberegler für die Sichtbarkeit auf 1 zu setzen. Wenn eine schnelle Korrektur gewünscht ist, verwenden man die Optionen 'Gesichter wiederherstellen' ('Restore Faces') und 'HighRes' in der Registerkarte Txt2Img. Wie im Beispielbild zu sehen ist, können diese Werkzeuge die Symmetrie verbessern und eventuelle Probleme mit den Augen beheben. Allerdings wird dadurch auch eine Glättung erzielt, und manchmal gehen dann ein paar Details verloren.
Das Prozedere lässt sich per Stapelverarbeitung automatisieren indem man ein Verzeichnis auf der Unterregisterkarte 'Stapelverarbeitung' (Batch Process) oder 'Stapel' (Batch) aus Verzeichnis auswählt.

Steps: 20
Sampler: DPM++ 2M
CFG scale: 6
Seed: 3876469716
Model: v2-1_512-ema-pruned
PNG-Info
Alle mit der webUI erstellten Bilder werden mit Metadaten gespeichert. Dazu gehören Informationen über alle Parameter, die für die Erstellung des Bildes verwendet wurden, den Prompt, der Sampler, der Seed, usw. Weiter oben findet sich ein Screenshot dieser Registerkarte (siehe Ausgabe). Eine weitere einfache Möglichkeit, die Metadaten im Auge zu behalten, ist die Bearbeitung des Dateinamens in den Einstellungen (Settings).
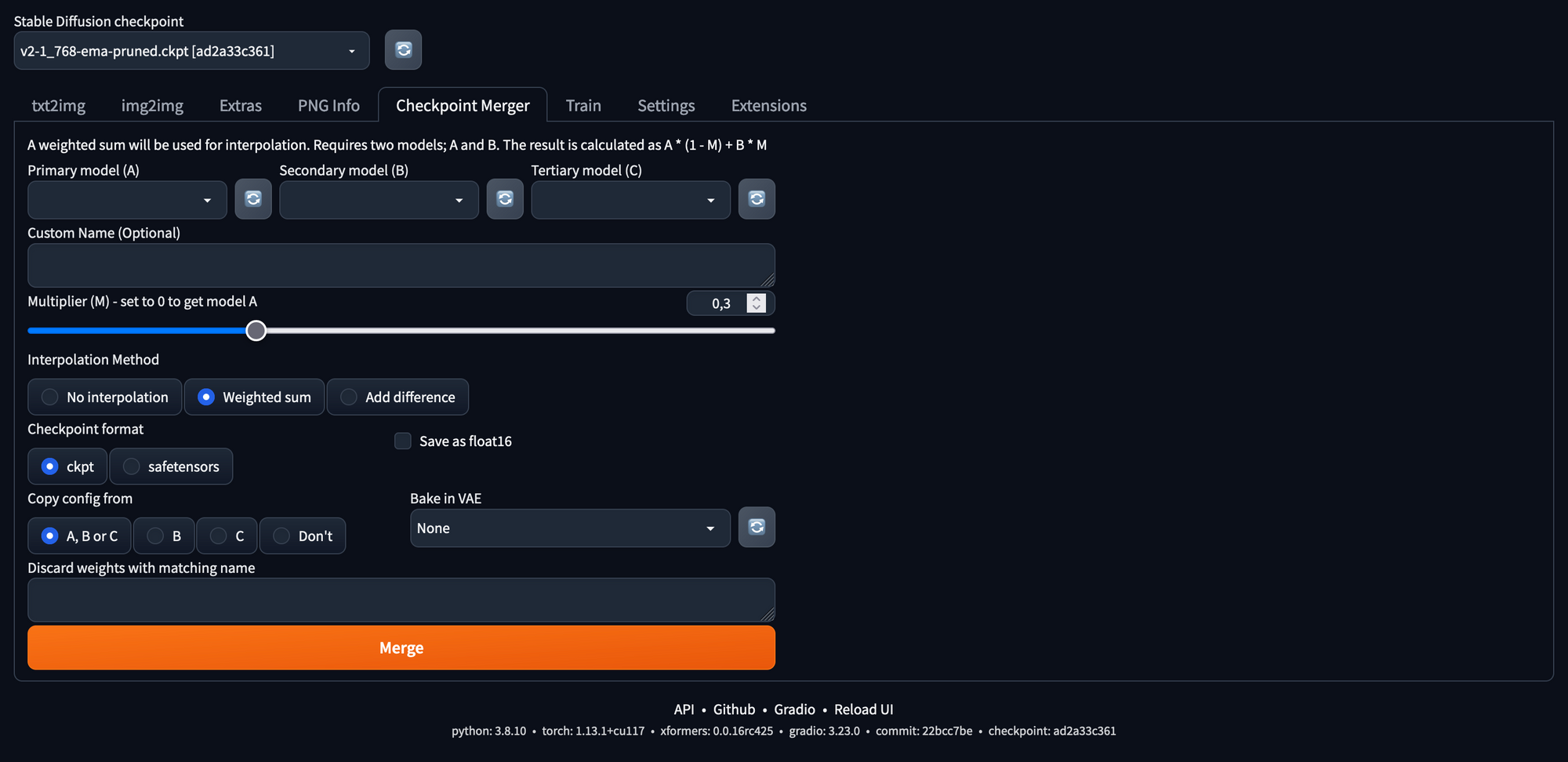
Checkpoint Merging
hier lassen sich verschiedene Checkpoints von Modellen zusammenführen. Wir werden in einem späteren Blog-Artikel detailliertere Informationen hierzu nachliefern. Eine kurze Einführung findet sich im Wiki.
Training
Die Möglichkeit zur Textuellen Inversion ist ebenfalls in der webUI enthalten. Dies ermöglicht es, das Modell mit eigenen Trainingsbildern zu personalisieren, und dies funktioniert mit den V2-Modellen viel besser als zuvor mit V1. Kurz gefasst erzeugt die Textuelle Inversion Embeddings, die den Trainingsdaten ähneln. Eine längere Erläuterung findet sich hier. Man kann sich diese Embeddings als Schlüsselwörter vorstellen, die als Platzhalter für sehr präzise Prompts fungieren. Wie man dies auf verschiedene Weise implementieren kann, wird in einem zukünftigen Blog-Artikel behandelt.
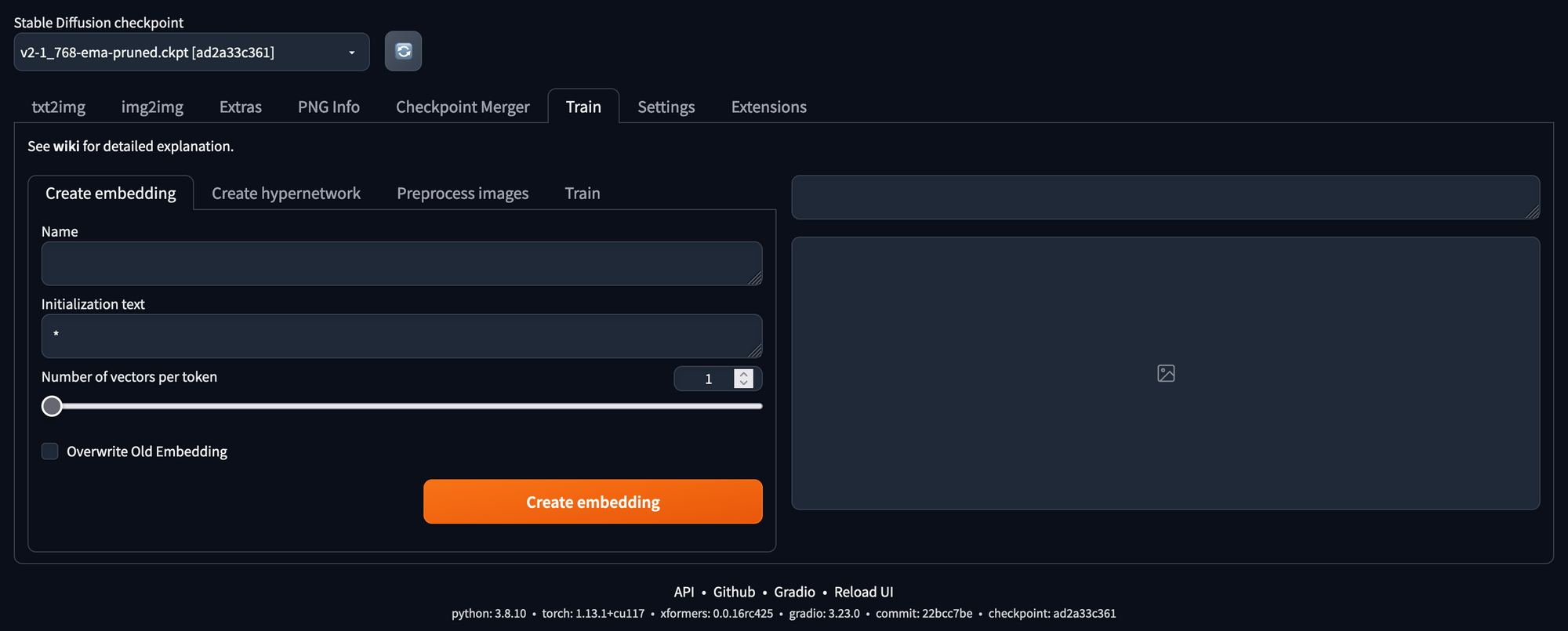
Anstatt eigene Einbettungen zu trainieren, lassen sich auch vorgefertigte Embeddings nutzen. Mit diesem Embedding wird zum Beispiel der Bildgenerierungs-Stil des Midjourney-Modells erwirkt. Man legt es in den Ordner /embeddings und startet webUI neu. Um das Embedding zu benutzen, gibt man die Schlüsselwörter art by midjourney (reddit-Link) ein. Es ist möglich, mehrere Embeddings zu verwenden, um Stile zu kombinieren.
Erweiterungen
Im Tab 'Erweiterungen' (Extensions) können der webUI benutzerdefinierte Funktionen hinzugefügt werden. Im Sub-Tab Available lassen sich mittels des Buttons 'Load from:' alle verfügbaren Erweiterungen auflisten.
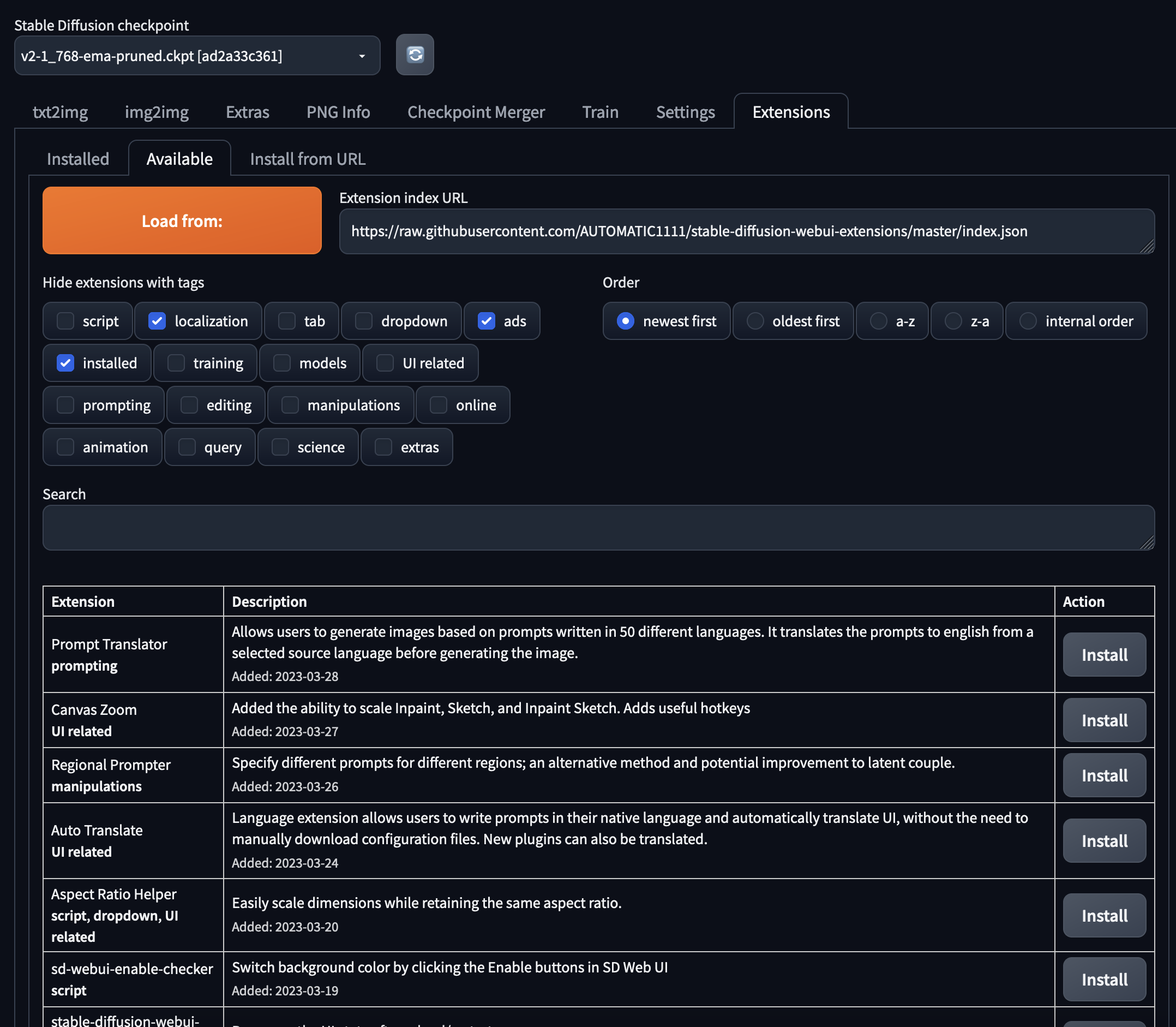
Eine andere Möglichkeit ist, das Repository der Erweiterung herunterzuladen oder in den Ordner extensions des AUTOMATIC1111-Repositorys stable-diffusion-webui zu klonen. Dieser Link bietet einen Überblick über die am häufigsten verwendeten Erweiterungen. Wir empfehlen für den Anfang:
- Image Browser: Ermöglicht es dem Benutzer, den Verlauf aller erzeugten Bilder zu sehen. Dies erleichtert das Auffinden alter Ausgaben und Metadaten, ohne den Datei-Explorer bemühen zu müssen.
- Depth Map: Erzeugt eine Tiefenkarte des Bildes, um den img2img-Prozess zu verbessern. Erlaubt dem Benutzer, eine zusätzliche Tiefendimension des Bildes im Skript-Bereich in der Registerkarte img2img zu nutzen.
- Auto-sd-paint: Ein ausgefeilteres Werkzeug zum Skizzieren mit dem Kreta-Plugin. Anleitungen für die Verwendung und Informationen über dieses Werkzeug finden sich auf der Wiki-Registerkarte dieser Erweiterung.
- Dreambooth: Eine weitere Möglichkeit zur Personalisierung oder Feinabstimmung der Modelle. Das Dreambooth-Thema wird in einem zukünftigen Blog-Beitrag ausführlicher behandelt.
- Deforum: Erstellt .gifs oder Videoausgaben für 2D- und 3D-Animationen.
- Outpainting: Ermöglicht die Ausweitung jedes Bild auf einer unendlichen Leinwand.
Command Line Argumente
Kommandozeilenargumente fügen webUI zusätzliche Funktionen hinzu oder passen die webUI an die eigenen Bedürfnisse oder Systemanforderungen an. Auf dieser Seite finden sich weitere Informationen über alle Argumente. Die Datei webui-user.sh lässt sich anpassen, um eigene Standard-Befehlszeilenargumente zu setzen. Dafür muss COMMANDLINE_ARGS= auskommentiert werden.
Hier sind ein paar nützliche Argumente:
- --xformers
Aktiviert die xformers-Bibliothek, die die Bilderzeugung beschleunigen und den Speicherbedarf der GPU reduzieren kann. Dies kann jedoch manchmal zu inkonsistenten Ergebnissen führen, insbesondere bei einem niedrigeren Wert für Steps. - --gradio-img2img-tool color sketch
Fügt eine Bearbeitungsfunktion zum Maskieren oder Skizzieren in der Registerkarte "img2img" hinzu. Diese Funktion funktioniert am besten im Chrome-Browser, da sie in Firefox ein wenig länger braucht. Eine weitere ausgefeiltere Option für img2img und auch Inpainting ist die auto-sd-paint Erweiterung mit dem Kreta-Plugin. - --gradio-inpaint-tool color sketch
Ermöglicht es dem Benutzer, eine farbige Maske für die Übermalung zu erstellen, wodurch die Konsistenz der Ergebnisse verbessert werden kann. - --device-id
Wird benötigt, um in einem Multi-GPU-Setup eine spezifische GPU auszuwählen. Manchmal muss vorher der Befehl export CUDA_VISIBLE_DEVICES=num_gpu ausgeführt werden.
Tips & Tricks
Multi-GPU
Die einzige Möglichkeit, mehrere GPUs zu verwenden, besteht darin, mehrere Instanzen zu betreiben. Hierzu exportiert man zunächst CUDA_VISIBLE_DEVICES= num_gpu und startet dann verschiedene webUIs mit dem Argument --device-id num_gpu. Es ist wichtig, dieses Argument als letztes Argument einzugeben. Wenn verschiedene webUIs gleichzeitig gestartet werden sollen, muss auch das Argument --port auf etwas anderes als den Standardwert 7860 gesetzt werden, um die webUI-Server getrennt voneinander ansurfen zu können.
In einem 2xGPU-System verwendet man z.B. am besten das Linux-Tool screen, um komfortabel innerhalb desselben MLC agieren zu können.
# screen session I
# this will open the webUI on the standard GPU and port (7860)
[webui-automatic1111] user@hostname:/workspace$
bash webui.sh --xformers
# screen session II
# this will open the webUI on the second GPU using port 7861
[webui-automatic1111] user@hostname:/workspace$
export CUDA_VISIBLE_DEVICES=1
bash webui.sh --xformers --port 7861 --device-id 0
Ausführung mit 'Accelerate'
Die Ausführung der webUI mit Accelerate verbessert die Effizienz und den Speicherverbrauch von Inferenz und Training. Hierzu wird in der Datei webui-user.sh das Kommentarzeichen vor export ACCELERATE="True" entfernt und die Anwendung neu gestartet.
Updates
Um immer mit den neuesten Funktionalitäten arbeiten zu können, ist es wichtig, webUI regelmäßig zu aktualisieren. Mittels git status lässt sich prüfen, ob es Aktualisierungen gibt, git pull synchronisiert die neuesten Änderungen:
[webui-automatic1111] user@hostname:/workspace$
git status
git pull
Die Aktualisierung der Erweiterungen kann in der webUI-Registerkarte "Erweiterungen" (Extensions) vorgenommen werden. Dort sucht man nach Updates, wendet sie an, startet webUI neu und lädt ebenfalls die Browser-Seite neu.
Nützliche Links
- AUTOMATIC1111 webUI
- Prompt-Bücher
- Suchmaschinen für die Bilderzeugung, zur Inspiration empfohlen
- Depth aware masking in img2img
- Erläuterung von Inpainting und Outpainting
- Andere webUI's:
- InvokeAI: ein sauberer aussehendes Web-Interface mit praktischen und robusten, aber viel weniger Funktionen. Da es nicht Open Source ist, wird InvokeUI nicht so häufig aktualisiert wie AUTOMATIC1111, aber die Updates sind weniger fehleranfällig. Die Installation erfordert 20 GB freien Speicherplatz ohne die Modelle.
- The Last Ben
Fazit
Wir haben gezeigt, dass die AUTOMATIC1111 webUI ein benutzerfreundliches Werkzeug für die Interaktion mit Stable Diffusion ist. Es ist einfach mit AIME MLC einzurichten und bietet eine breite Palette von Funktionen und Vorteilen gegenüber der Konsolen-Nutzung. Die wichtigsten Aspekte der webUI wurden erläutert und die Unterschiede zwischen den Stable Diffusion-Versionen anhand von Beispielen aufgezeigt. Es wurden einige Tipps und Tricks gegeben, um das Beste aus Stable Diffusion auf Ihrer AIME Workstation oder Ihrem Server herauszuholen. Insgesamt ist die AUTOMATIC1111 webUI eine wertvolle Ressource für alle, die mit der generativen Bilderzeugung experimentieren möchten.
Fragen oder Anregungen bitte per E-Mail an hello@aime info.